This method is particularly valuable in fields like chatbot development, where the ability to provide precise answers derived from extensive databases of knowledge is crucial.
RAG fundamentally enhances the natural language understanding and generation capabilities of models by allowing them to access and leverage a vast amount of external knowledge. The approach is built upon the synergy between two main components: a retrieval system and a generative model. The retrieval system first identifies relevant information from a knowledge base, which the generative model then uses to craft responses that are not only accurate but also rich in detail and scope.
Types of RAG
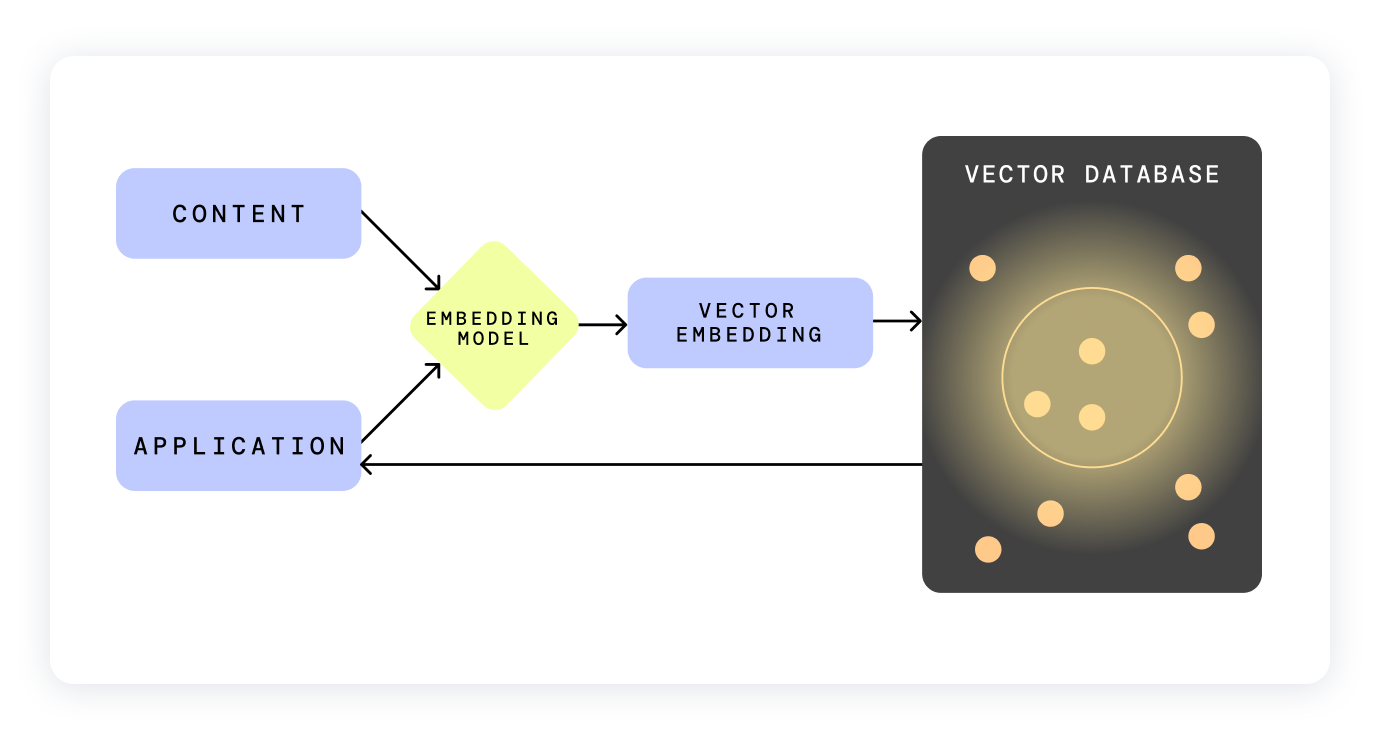
Vector-based RAG - the most common type of RAG.
You convert text into “embeddings” and store them in a vector database.
Overview showing RAG with a Vector DB
Vector databases enable search functions that are much better than typical keyword searches. If users are looking for data that has semantic similarity, a vector database can often help them find those data points, even if there isn’t a literal keyword match
The downside is the context can be lost, especially when its relational context between data points. When chunking vectors, they use data-point similarity based on nearness. See KNN (k-nearest neighbors) and ANN (Approximate Nearest Neighbor)
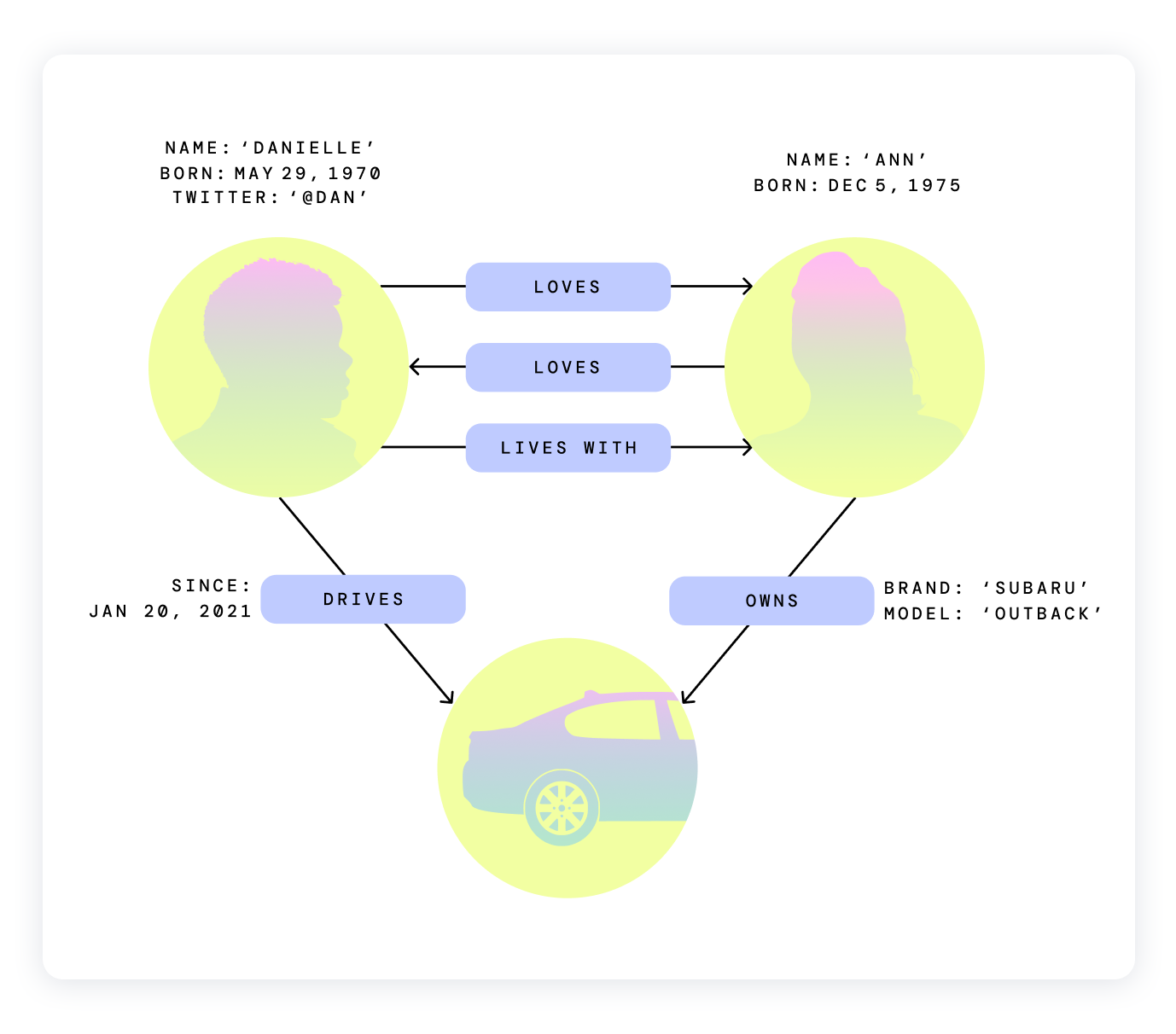
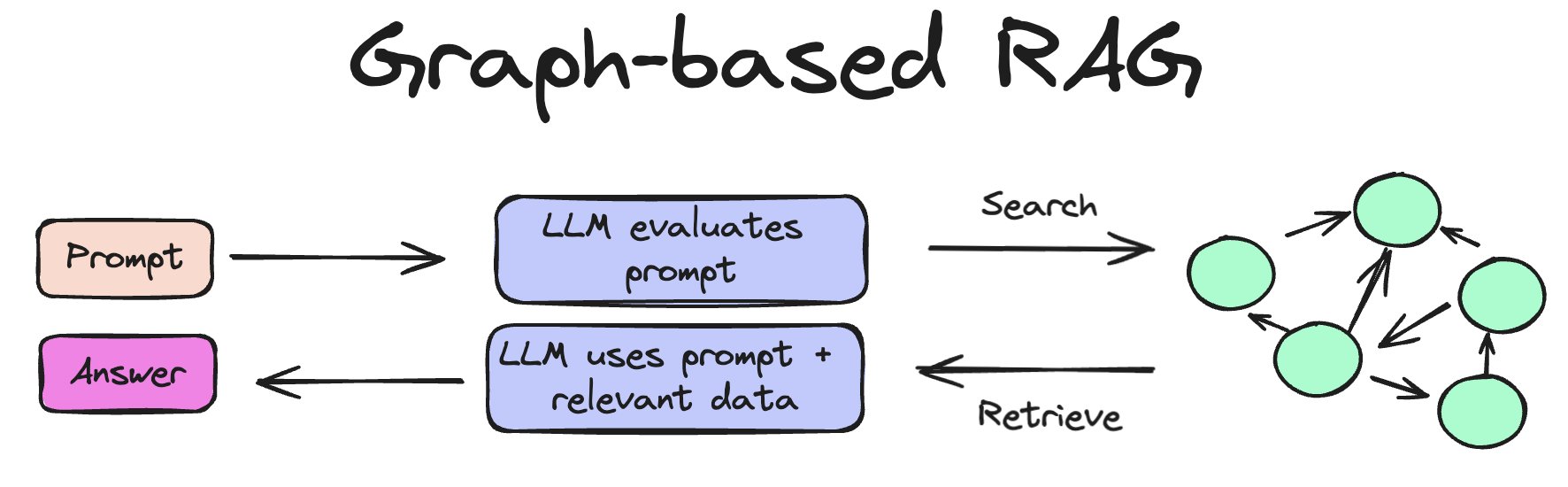
Graph-based RAG
Instead of using a vector database, you use a Graph Database. A Graph DB contains vector information where links also store data. This allows relational information from retrieval
Svelte is a component-based JavaScript framework that compiles your code at build time rather than at runtime. This means that instead of shipping a bulky framework to the client, Svelte generates highly optimized vanilla JavaScript code that updates the DOM. This approach results in faster load times and better performance. Additionally, Svelte has a small API surface area, making it easy to learn and use.
The following example is a simple counter application that teaches the basics of Svelte.
<script> let count = 0; function increment() { count += 1; } function decrement() { count -= 1; }</script><main> <h1>The count is {count}</h1> <button on:click={decrement}>-</button> <button on:click={increment}>+</button></main><style> main { text-align: center; padding: 1em; } button { margin: 0 1em; padding: 0.5em 1em; }</style>
The count is 0
Reactive Variables: let count = 0; This variable is reactive. Any changes to count will automatically update the DOM wherever count is referenced.
Event Handling: The on:click directive is used to attach click event listeners to both buttons, calling the increment and decrement functions accordingly.
Inline Handlers: If you prefer, you could inline these functions directly in the on:click handler for something even simpler, like on:click={() => count += 1}.
Conditional Rendering: Suppose you want to display a message when the count is above a certain threshold. You can use an {#if} block directly in your HTML:
{#if count > 10} <p>You have reached a count greater than 10!</p>{/if}
Svelte Components
Expanding our simple counter application by breaking it down into smaller components, which is a common practice for improving the organization and reusability of your code in larger applications. We’ll create two components: CounterDisplay for showing the current count and CounterButton for the increment and decrement buttons.
Create a new file named CounterDisplay.svelte in the src directory. This component will be responsible for displaying the count.
<script> // This component accepts a prop named `count` export let count;</script><h1>The count is {count}</h1>
Create another file named CounterButton.svelte in the src directory. This component will represent a button that can increment or decrement the counter.
<script> // The component accepts two props: the button text and the click action export let text; export let handleClick;</script><button on:click={handleClick}>{text}</button>
Now, update the App.svelte file to use these new components.
<script> import CounterDisplay from './CounterDisplay.svelte'; import CounterButton from './CounterButton.svelte'; let count = 0; function increment() { count += 1; } function decrement() { count -= 1; }</script><main> <CounterDisplay {count} /> <CounterButton text="-" handleClick={decrement} /> <CounterButton text="+" handleClick={increment} /></main><style> main { text-align: center; padding: 1em; }</style>
Props: Components in Svelte can accept “props”, which are custom attributes passed into components. In our case, CounterDisplay accepts a count prop, and CounterButton accepts text and handleClick props. This allows the components to be reusable and dynamic. Props are reactive, where any prop changes will trigger changes in the component.
Component Interaction: The App.svelte component manages the state (count) and functions (increment and decrement) and passes them down to the child components. This demonstrates a fundamental pattern of component-based architecture: lifting state up and passing data and behavior down through props.
Event Handling in Child Components: The CounterButton component receives a function (handleClick) as a prop and attaches it to the button’s click event. This is a common pattern for handling events in child components and allowing parent components to define the behavior.
Slots in Svelte
Slots in Svelte allow you to create components that can accept content dynamically from their parents. This is similar to transclusion or content projection in other frameworks. In other libraries like React, this is handled with children. Slots make components more flexible by letting you inject content into predefined places within a component’s template.
Basic Slot Example
Imagine you’re building a Card component that you want to reuse across your application, but with different content each time.
Card.svelte:
<div class="card"> <slot></slot> <!-- This is where the parent's content will be injected --></div><style> .card { border: 1px solid #ccc; border-radius: 8px; padding: 20px; margin: 10px 0; }</style>
You can use this Card component in a parent component and pass in different content like so:
<script> import Card from './Card.svelte';</script><Card> <h2>Title</h2> <p>This is some card content.</p></Card><Card> <p>Another card with different content.</p></Card>
Named Slots
Svelte also supports named slots, which allow you to define multiple slots within a single component.
Card.svelte updated with named slots:
<div class="card"> <header> <slot name="header"></slot> <!-- Named slot for header content --> </header> <slot></slot> <!-- Default slot for main content --> <footer> <slot name="footer"></slot> <!-- Named slot for footer content --> </footer></div>
Module scripts in Svelte introduce a powerful feature for managing reusable code and behaviors in your components. A module script runs once when a component is first imported, rather than each time a component instance is created. This makes it ideal for defining shared logic, helpers, and stores that can be used across all instances of a component.
To define a module script in a Svelte component, you use the <script context="module"> tag. Anything declared inside this tag is scoped to the module, not to individual instances of the component. This is particularly useful for situations where you want to maintain a shared state or perform actions that only need to happen once, regardless of how many times a component is instantiated.
Here’s a simple example:
Counter.svelte:
<script context="module"> // This count is shared across all instances of Counter.svelte let count = 0; export function increment() { count += 1; console.log(count); }</script><script> // This script block is for instance-specific logic and state import { onMount } from 'svelte'; onMount(() => { // Call the shared increment function when the component mounts increment(); });</script><p>This component has been instantiated.</p>
In this example, the increment function and the count variable are defined in a module script and shared across all instances of Counter.svelte. Every time a new instance is created, it logs the incremented count, demonstrating that count is shared and persists across instances.
Use Cases for Module Scripts
Defining shared utility functions: For components that require common functionality, you can define utility functions in a module script to avoid duplicating code.
Creating singleton stores: If you need a store that’s shared across all instances of a component, defining it in a module script ensures that you have a single, shared store.
Optimizing performance: Since code in a module script is executed only once, it’s an excellent place for performing expensive operations like setting up subscriptions or fetching data that should be done once per component type, rather than once per instance.
Advanced Component Composition
Module scripts complement Svelte’s component composition model by allowing you to abstract and share logic effectively. For instance, you can combine module scripts with slots, props, and context to create highly reusable and customizable components.
Imagine a scenario where you’re building a library of UI components. Using module scripts, you can provide a consistent API for configuring these components globally (like themes or internationalization settings) while using instance scripts for configuration that is specific to a component’s use case.
Considerations
Scoping: Remember that variables and functions declared in module scripts are not directly accessible in the instance script or the component’s markup. To use them in the component, they need to be exported from the module script and then imported or used in the instance script.
Singleton behavior: Since the module scope is shared across instances, be mindful of side effects that might occur when modifying shared state. This is similar to how static variables would behave in class-based languages.
Stores for State Management
Svelte Stores takes a reactive approach to state management, which is different than Redux. At the core of it, see the following.
Creating a Store: The simplest form of a store in Svelte is a writable store. For example, creating a store to hold a number could look like this:
import { writable } from "svelte/store";const count = writable(0);
Subscribing to a Store: To access the value of a store outside of a Svelte component, you subscribe to it. This might be where syntax can get tricky. Use the $: syntax intuitive for reactive statements. Alternatively, you can directly subscribe using .subscribe method.
Updating Store Values: Svelte provides a few patterns for updating the store’s value, such as set, update, and using the auto-subscription feature within components with the $ prefix.
Reactivity: One of the powerful features of Svelte is its built-in reactivity. Reactive variables automatically propagate through your application.
Derived Stores
Derived stores let you create a store based on other store(s), automatically updating when the underlying stores change. This is useful for calculating derived values or aggregating data from multiple sources.
Example:
Suppose you have a store for a list of items and another derived store that calculates the total number of items.
For applications with complex state, consider structuring your store as a JavaScript object or even using a custom store. Custom stores can encapsulate more complex behavior, such as asynchronous operations or integration with external data sources.
Creating a Custom Store:
function createCustomStore() { const { subscribe, set, update } = writable(initialValue); return { subscribe, // Custom methods to interact with the store increment: () => update((n) => n + 1), decrement: () => update((n) => n - 1), reset: () => set(initialValue), // More complex operations... };}
Slots and advanced state management techniques in Svelte offer a combination of simplicity and power, enabling you to build complex and dynamic applications with less code and more declarative, readable structures.
Actions
Svelte actions are a powerful and somewhat under-appreciated feature that provide a neat way to interact with DOM elements directly. Actions allow you to attach reusable behavior to DOM elements, which can be especially useful for integrating third-party libraries or creating custom directives that enhance your application’s functionality without cluttering your components with imperative code.
An action is simply a function that is called when a DOM element is created, and it returns an object that can contain lifecycle methods like update and destroy. Here’s a basic outline of how actions work:
Creating an Action: To create an action, you define a function that takes at least one argument, the element it’s attached to. This function can return an object with optional update and destroy methods. The update method is called whenever the parameters of the action change, and destroy is called when the element is removed from the DOM.
Using an Action: You apply an action to a DOM element in your Svelte component using the use directive.
Here’s a simple example to illustrate:
Defining a Simple Action
Let’s say you want to create an action that automatically focuses an input element when the component mounts:
// focus.jsexport function autofocus(node) { // Directly focus the DOM node node.focus(); // No need for update or destroy in this case, but they could be added if necessary}
Applying the Action in a Component
You can then use this action in any component like so:
<script> import { autofocus } from './focus.js';</script><input use:autofocus />
This example is quite basic, but actions can be much more complex and powerful. For instance, you could create an action to:
Implement drag-and-drop functionality by attaching mouse event listeners to the element.
Integrate with third-party libraries, such as initializing a date picker on an input element.
Add custom animations or transitions that are not easily achieved through Svelte’s native capabilities.
Svelte makes adding animations and transitions to your web applications straightforward and intuitive, enhancing user experience with visual feedback and smooth transitions. Let’s explore how to add a simple fade transition to elements in a Svelte application, and then we’ll look at a more interactive example.
Transitions and Animations
Svelte’s transition functions, such as fade, are part of the svelte/transition module. To use a fade transition on an element, first import fade from this module.
Example:
<script> import { fade } from 'svelte/transition'; let isVisible = true;</script><button on:click={() => (isVisible = !isVisible)}> Toggle</button>{#if isVisible} <div transition:fade={{ duration: 300 }}> Fade me in and out </div>{/if}
In this example, clicking the “Toggle” button shows or hides the div element with a fade effect over 300 milliseconds.
Fade me in and out
Interactive Animation Example
For a more interactive example, let’s create a list where items can be added and removed, each with an animation. We’ll use the slide transition to make items slide in and out.
First, add slide to your imports:
<script> import { slide } from 'svelte/transition'; let items = ['Item 1', 'Item 2', 'Item 3'];</script>
Now, create a function to add a new item and another to remove an item:
function addItem() { items = [...items, `Item ${items.length + 1}`];}function removeItem(index) { items = items.filter((_, i) => i !== index);}
Finally, render the list with transitions on each item:
In the #each block, we use the slide transition to animate the addition and removal of list items. The (item) key ensures that Svelte can uniquely identify each item for correct animation, especially during removals.
Item 1
Item 2
Item 3
Customizing Transitions
Svelte’s transitions can be customized extensively via parameters. For both fade and slide, you can adjust properties like duration, delay, and easing (to control the animation’s timing function). Svelte also supports custom CSS transitions and animations, giving you complete control over your animations’ look and feel.
Using the Basic Svelte Template
If you’re looking for something simpler or specifically want to work with just the Svelte library without the additional features offered by SvelteKit, you can start with the basic Svelte template.
The 7 GUIs is a benchmark for comparing different GUI frameworks, proposed by Eugen Kiss. See his explanation below.
There are countless GUI toolkits in different languages and with diverse approaches to GUI development.
Yet, diligent comparisons between them are rare.
Whereas in a traditional benchmark competing implementations are compared in terms of their resource consumption,
here implementations are compared in terms of their notation.
To that end, 7GUIs defines seven tasks that represent typical challenges in GUI programming.
In addition, 7GUIs provides a recommended set of evaluation dimensions.
— Eugen Kiss
I’m going to walkthrough each GUI using Svelte, and annotate the code.
Counter
The task is to build a frame containing a label or read-only textfield T and a button B.
Initially, the value in T is “0” and each click of B increases the value in T by one.
<script> // Initialize the counter with "0" (as it says in the spec) let count = 0;</script><!-- Display the count, as a number input --><input type="number" bind:value={count}/><!-- Add a button that will increment the counter by 1 with each click. --><button on:click={() => (count += 1)}>count</button>
Temperature
The task is to build a frame containing two textfields TC and
TF representing the temperature in Celsius and Fahrenheit,
respectively. Initially, both TC and TF are empty. When
the user enters a numerical value into TC the corresponding value
in TF is automatically updated and vice versa. When the user enters
a non-numerical string into TC the value in TF is not
updated and vice versa. The formula for converting a temperature C in Celsius
into a temperature F in Fahrenheit is C = (F - 32) * (5/9) and the dual
direction is F = C * (9/5) + 32.
<script lang="ts"> // Initialize the values of celsius and fahrenheit let c = 20; let f = 68; // Given the value from Celsius, update Fahrenheit function setBothFromC(value: number): void { // The + is to convert the string to a number c = +value; // Use the formula from the spec to update fahrenheit f = +(32 + (9 / 5) * c).toFixed(1); } // Given the value from Fahrenheit, update Celsius function setBothFromF(value: number): void { f = +value; // Use the formula from the spec to update celsius c = +((5 / 9) * (f - 32)).toFixed(1); }</script><!--Add two different inputs. Since the inputs are two-way bound by the values,`c` and `f`, we can add an event listener to run the function to convert theother value.--><input value={c} on:input={(e) => setBothFromC(e.target.value)} type="number"/>°C =<input value={f} on:input={(e) => setBothFromF(e.target.value)} type="number"/>°F
Flight Booker
The task is to build a frame containing a form with three textfields
The task is to build a frame containing a combobox C with the two options
“one-way flight” and “return flight”, two textfields T1 and
T2 representing the start and return date, respectively, and a
button B for submitting the selected flight. T2 is enabled iff C’s
value is “return flight”. When C has the value “return flight” and
T2’s date is strictly before T1’s then B is disabled.
When a non-disabled textfield T has an ill-formatted date then T is colored
red and B is disabled. When clicking B a message is displayed informing the
user of his selection (e.g. “You have booked a one-way flight on
04.04.2014.”). Initially, C has the value “one-way flight” and T1
as well as T2 have the same (arbitrary) date (it is implied that
T2 is disabled).
<script> const DAY_IN_MS = 86400000 const tomorrow = new Date(Date.now() + DAY_IN_MS); // Create an array of year, month, day, in this format: YYYY-MM-DD let start = [ tomorrow.getFullYear(), pad(tomorrow.getMonth() + 1, 2), pad(tomorrow.getDate(), 2), ].join("-"); // our reactive variables let end = start; let isReturn = false; // Running statements reactively, updating the variables when they are changed $: startDate = convertToDate(start); $: endDate = convertToDate(end); // Click handler for the button function bookFlight() { // Determine type of return const type = isReturn ? "return" : "one-way"; let message = `You have booked a ${type} flight, leaving ${startDate.toDateString()}`; if (type === "return") { message += ` and returning ${endDate.toDateString()}`; } alert(message); } // Convert a string in the format YYYY-MM-DD to a Date object function convertToDate(str) { const split = str.split("-"); return new Date(+split[0], +split[1] - 1, +split[2]); } // Pad a number with leading zeros function pad(x, len) { x = String(x); while (x.length < len) x = `0${x}`; return x; }</script><!-- Create your select input for one-way or return flight option --><select bind:value={isReturn}> <option value={false}>one-way flight</option> <option value={true}>return flight</option></select><!-- Bind the inputs --><input type="date" bind:value={start} /><input type="date" bind:value={end} disabled={!isReturn} /><!-- Attempt to book flight --><button on:click={bookFlight} disabled={isReturn && startDate >= endDate} >book</button>
Timer
The task is to build a frame containing a gauge G for the elapsed time e, a
label which shows the elapsed time as a numerical value, a slider S by which
the duration d of the timer can be adjusted while the timer is running and a
reset button R. Adjusting S must immediately reflect on d and not only when S
is released. It follows that while moving S the filled amount of G will
(usually) change immediately. When e ≥ d is true then the timer stops (and G
will be full). If, thereafter, d is increased such that d > e will be true
then the timer restarts to tick until e ≥ d is true again. Clicking R will
reset e to zero.
<script> // It turns out, you can't run this in Astro without saying this component is client only import { onDestroy } from "svelte"; // Start elapsed at 0 milliseconds let elapsed = 0; // Set the range input to be 5 seconds / 5000 milliseconds let duration = 5000; let last_time = window.performance.now(); let frame; // IIFE for animation loop (function update() { // pass in the function for the animation frame (infinite looping) frame = requestAnimationFrame(update); // performance.now() is like Date.now(), but more accurate to tenths of a milliseconds const time = window.performance.now(); // Take the minimum of the time elapsed and add it to the new elapsed time elapsed += Math.min(time - last_time, duration - elapsed); last_time = time; })(); // When the component is destroyed, cancel the animation frame onDestroy(() => { cancelAnimationFrame(frame); });</script><!-- Create the label and use the progress tag to show the time elapsed vs duration --><label> elapsed time: <progress value={elapsed / duration} /></label><div>{(elapsed / 1000).toFixed(1)}s</div><label> duration: <!-- Bind the input to the duration. Max 20 seconds --> <input type="range" bind:value={duration} min="1" max="20000" /></label><!-- Allow the user to reset the timer --><button on:click={() => (elapsed = 0)}>reset</button>
CRUD
The task is to build a frame containing the following elements: a textfield
Tprefix, a pair of textfields Tname and
Tsurname, a listbox L, buttons BC, BU and
BD and the three labels as seen in the screenshot. L presents a
view of the data in the database that consists of a list of names. At most one
entry can be selected in L at a time. By entering a string into
Tprefix the user can filter the names whose surname start with the
entered prefix—this should happen immediately without having to submit the
prefix with enter. Clicking BC will append the resulting name from
concatenating the strings in Tname and Tsurname to L.
BU and BD are enabled if an entry in L is selected. In
contrast to BC, BU will not append the resulting name
but instead replace the selected entry with the new name. BD will
remove the selected entry. The layout is to be done like suggested in the
screenshot. In particular, L must occupy all the remaining space.
<script> // Have some people to start with let people = [ { first: "Hans", last: "Emil" }, { first: "Max", last: "Mustermann" }, { first: "Roman", last: "Tisch" }, ]; // Initialize the bound variables let prefix = ""; let first = ""; let last = ""; // Initialize the selected item index let i = 0; // Reactive statements when the changes $: filteredPeople = prefix ? people.filter((person) => { const name = `${person.last}, ${person.first}`; // Filter based off first or last name return name.toLowerCase().startsWith(prefix.toLowerCase()); }) : people; // Reactively change the selected when filtered people $: selected = filteredPeople[i]; // Reset all inputs when new selection made $: reset_inputs(selected); // Create a new person function create() { people = people.concat({ first, last }); i = people.length - 1; first = last = ""; } // Update the selected person function update() { selected.first = first; selected.last = last; people = people; } // Remove the selected person function remove() { // Remove selected person from the source array (people), not the filtered array const index = people.indexOf(selected); people = [...people.slice(0, index), ...people.slice(index + 1)]; first = last = ""; i = Math.min(i, filteredPeople.length - 2); } // Reset the input for first and last names function reset_inputs(person) { first = person ? person.first : ""; last = person ? person.last : ""; }</script><input placeholder="filter prefix" bind:value={prefix}/><select bind:value={i} size={5}> <!-- Loop through the filtered people --> {#each filteredPeople as person, i} <option value={i}>{person.last}, {person.first}</option> {/each}</select><!-- Create inputs for first and last names --><label ><input bind:value={first} placeholder="first" /></label><label ><input bind:value={last} placeholder="last" /></label><!-- CRUD operators --><div class="buttons"> <button on:click={create} disabled={!first || !last}>create</button> <button on:click={update} disabled={!first || !last || !selected} >update</button > <button on:click={remove} disabled={!selected}>delete</button></div>
Circle Drawer
The task is to build a frame containing an undo and redo button as well as a
canvas area underneath. Left-clicking inside an empty area inside the canvas
will create an unfilled circle with a fixed diameter whose center is the
left-clicked point. The circle nearest to the mouse pointer such that the
distance from its center to the pointer is less than its radius, if it exists,
is filled with the color gray. The gray circle is the selected circle C.
Right-clicking C will make a popup menu appear with one entry “Adjust
diameter…”. Clicking on this entry will open another frame with a slider
inside that adjusts the diameter of C. Changes are applied immediately.
Closing this frame will mark the last diameter as significant for the
undo/redo history. Clicking undo will undo the last significant change (i.e.
circle creation or diameter adjustment). Clicking redo will reapply the last
undoed change unless new changes were made by the user in the meantime.
<script> // Initialize the bound variables let i = 0; let undoStack = [[]]; let circles = []; let selected; let adjusting = false; let adjusted = false; // On handling click, create circle with default radius 50 px function handleClick(event) { if (adjusting) { adjusting = false; // if circle was adjusted, // push to the stack if (adjusted) push(); return; } const circle = { cx: event.clientX, cy: event.clientY, r: 50, }; // Add circles to list of circles. The selected circle is the current circle circles = circles.concat(circle); selected = circle; push(); } function adjust(event) { selected.r = +event.target.value; circles = circles; adjusted = true; } function select(circle, event) { if (!adjusting) { event.stopPropagation(); selected = circle; } } // Use a stack for keeping track of the circles function push() { const newUndoStack = undoStack.slice(0, ++i); newUndoStack.push(clone(circles)); undoStack = newUndoStack; } function travel(d) { circles = clone(undoStack[(i += d)]); adjusting = false; } function clone(circles) { return circles.map(({ cx, cy, r }) => ({ cx, cy, r })); }</script><!-- Put in the buttons for controls --><div class="controls"> <button on:click={() => travel(-1)} disabled={i === 0}>undo</button> <button on:click={() => travel(+1)} disabled={i === undoStack.length - 1} >redo</button ></div><!-- Draw with an SVG. Bind the click handler --><!-- svelte-ignore a11y-click-events-have-key-events a11y-no-static-element-interactions --><svg on:click={handleClick}> <!-- Draw all of the circles --> {#each circles as circle} <!-- svelte-ignore a11y-click-events-have-key-events --> <circle cx={circle.cx} cy={circle.cy} r={circle.r} on:click={(event) => select(circle, event)} on:contextmenu|stopPropagation|preventDefault={() => { // When right-clicking, open the adjuster adjusting = !adjusting; if (adjusting) selected = circle; }} fill={circle === selected ? "#ccc" : "white"} /> {/each}</svg><!-- Show the adjuster if adjusting a circle's size -->{#if adjusting} <div class="adjuster"> <p>adjust diameter of circle at {selected.cx}, {selected.cy}</p> <input type="range" value={selected.r} on:input={adjust} /> </div>{/if}
Cells
The task is to create a simple but usable spreadsheet application. The
spreadsheet should be scrollable. The rows should be numbered from 0 to 99 and
the columns from A to Z. Double-clicking a cell C lets the user change C’s
formula. After having finished editing the formula is parsed and evaluated and
its updated value is shown in C. In addition, all cells which depend on C must
be reevaluated. This process repeats until there are no more changes in the
values of any cell (change propagation). Note that one should not just
recompute the value of every cell but only of those cells that depend on
another cell’s changed value. If there is an already provided spreadsheet
widget it should not be used. Instead, another similar widget (like JTable in
Swing) should be customized to become a reusable spreadsheet widget.
This one isn’t in the Svelte documentation, so I found a different
implementation that went through it perfectly. Link
Cells is split up into two Svelte components: Cell and Cells.
<!-- Cell.svelte --><script> // Initialized props export let j; export let i; export let focused; export let data; export let p; export let handleFocus; export let handleBlur; export let handleKeydown; export let handleInput; // Keep track of the current key let key = j + i; // Keep track if a cell is focused let hasFocus = false; $: if (focused === key && !hasFocus) { hasFocus = true; } else if (focused !== key && hasFocus) { hasFocus = false; }</script><!-- When focused, change the cell into an input --><!-- Otherwise parse the formula -->{#if hasFocus} <input id={"input-" + key} value={$data[key] || ""} autofocus on:focus={() => handleFocus(key)} on:blur={() => handleBlur(key)} on:keydown={(e) => handleKeydown(e, j, i)} on:input={(e) => handleInput(e, key)} />{:else} <div>{p.parse($data[key]) || ""}</div>{/if}
<!-- Cells.svelte --><script> import Cell from "./Cell.svelte"; import { data } from "./store.js"; import { sampleData } from "./sampleData.js"; import { Parser } from "./parse.js"; // Initialize with the sample data set data.set(sampleData); // Create 26 columns w/ the letters of the alphabet const LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; // Max 100 x 100 cells export let shape = [100, 100]; const rows = range(shape[1]); const columns = letterRange(shape[0]); const p = new Parser(data, columns, rows); let focused; let tBody; // Create range array function range(n) { return [...Array(n).keys()]; } // Create letter range function letterRange(n) { return range(n).map(getNumberAsLetters); } // Loop through letters function getBase26(n) { let result = []; while (n > 25) { let remainder = n % 26; result.push(remainder); n = Math.floor(n / 26) - 1; } result.push(n); return result.reverse(); } // Get the letter range and join them function getNumberAsLetters(n) { let arr = getBase26(n); return arr.map((num) => LETTERS[num]).join(""); } function handleFocus(key) { if (focused !== key) { $data[key] = $data[key] || ""; focused = key; setTimeout(() => { let target = tBody.querySelector("#input-" + key); if (target) { target.focus(); target.setSelectionRange(0, 9999); } }, 10); } } function handleBlur(key) { if (focused === key) focused = undefined; } function handleInput(e, key) { $data[key] = e.target.value; } function handleKeydown(e, column, row) { // Navigate across the spreadsheet with arrow keys (and alt/option key) let selector; if (e.key === "ArrowUp") { let newRow = findAdjacent(rows, row, "before"); selector = newRow !== null ? column + newRow : null; } if (e.key === "ArrowDown" || e.key === "Enter") { let newRow = findAdjacent(rows, row, "after"); selector = newRow !== null ? column + newRow : null; } if (e.key === "ArrowLeft" && e.altKey) { let newColumn = findAdjacent(columns, column, "before"); selector = newColumn !== null ? newColumn + row : null; } if (e.key === "ArrowRight" && e.altKey) { let newColumn = findAdjacent(columns, column, "after"); selector = newColumn !== null ? newColumn + row : null; } if (selector) { e.preventDefault(); handleFocus(selector); } } function findAdjacent(arr, value, direction) { let index = arr.indexOf(value); if (index === -1) return null; if (direction === "before") return arr[index - 1] === undefined ? null : arr[index - 1]; if (direction === "after") return arr[index + 1] || null; return null; } function clear() { data.set({}); }</script><div class="wrapper"> <table> <thead> <tr> <td class="row-key" /> {#each columns as column} <td class="column-key">{column}</td> {/each} </tr> </thead> <tbody bind:this={tBody}> {#each rows as i} <tr id={"row-" + i}> <td class="row-key">{i}</td> {#each columns as j} <td id={j + i} on:click={() => handleFocus(j + i)}> <Cell {j} {i} {focused} {data} {p} {handleFocus} {handleBlur} {handleKeydown} {handleInput} /> </td> {/each} </tr> {/each} </tbody> </table></div><button on:click={clear}>Clear</button>
There are two utility functions to help out the operations: parse and store
(the latter being the Svelte store to save in local state).
// parse.jsexport class Parser { constructor(store, columns, rows) { this.cells = {} this.store = store this.columns = columns this.rows = rows this.operations = { sum: (a, b) => a + b, sub: (a, b) => a - b, mul: (a, b) => a * b, div: (a, b) => a / b, mod: (a, b) => a % b, exp: (a, b) => a ** b } // subscribe to store this.store.subscribe(value => { this.cells = value }) } cartesianProduct(letters, numbers) { var result = [] letters.forEach(letter => { numbers.forEach(number => { result.push(letter + number) }) }) return result } findArrRange(arr, start, end) { let startI = arr.indexOf(start) let endI = arr.indexOf(end) if (startI == -1 || endI == -1 || startI > endI) return [] return arr.slice(startI, endI + 1) } getRange(rangeStart, rangeEnd) { rangeStart = this.splitOperand(rangeStart) rangeEnd = this.splitOperand(rangeEnd) let letters = this.findArrRange(this.columns, rangeStart[0], rangeEnd[0]) let numbers = this.findArrRange(this.rows, rangeStart[1], rangeEnd[1]) return this.cartesianProduct(letters, numbers) } splitOperand(operand) { return [operand.match(/[a-zA-Z]+/)[0], Number(operand.match(/\d+/)[0])] } rangeOperation(op, rangeStart, rangeEnd) { if (!(this.isWellFormed(rangeStart) && this.isWellFormed(rangeEnd))) return this.originalString let range = this.getRange(rangeStart, rangeEnd) return range .map(address => Number(this.parse(this.cells[address]))) .reduce(this.operations[op]) } singleOperation(op, operand1, operand2) { let first = this.parseOperand(operand1) let second = this.parseOperand(operand2) if (first === null || second === null) return this.originalString return this.operations[op](first, second).toString() } isWellFormed(operand) { return /[a-zA-Z]+\d+/.test(operand) } parseOperand(operand) { if (!isNaN(Number(operand))) return Number(operand) if (operand in this.cells) return Number(this.parse(this.cells[operand])) if (this.isWellFormed(operand)) return 0 return null } parseOperation(op, formula) { if (!(formula.startsWith('(') && formula.endsWith(')'))) return this.originalString formula = formula.slice(1, formula.length - 1) let operationType let formulaArr if (formula.includes(',')) { operationType = 'single' formulaArr = formula.split(',') } else if (formula.includes(':')) { operationType = 'range' formulaArr = formula.split(':') } if (formulaArr.length !== 2) return this.originalString if (operationType === 'single') return this.singleOperation(op, formulaArr[0], formulaArr[1]) if (operationType === 'range') return this.rangeOperation(op, formulaArr[0], formulaArr[1]) return this.originalString } parse(str) { this.originalString = str if (typeof str !== 'string') return '' if (!str.startsWith('=')) return str let formula = str.slice(1) if (formula.slice(0, 3).toLowerCase() in this.operations) { return this.parseOperation( formula.slice(0, 3).toLowerCase(), formula.slice(3).toUpperCase() ) } else { return this.cells[formula] || str } }}
// store.jsimport { writable } from "svelte/store";export const data = writable({});
The last file is to load prefilled data, but we don’t need to go over that.
// An example of the sampleData fileexport let sampleData = { A0: "Data", A1: "20", A2: "15"};
SolidJS is a Javascript framework for building fast, declarative UIs on the web. It shares many ideas with React, but does not use the virtual DOM to deliver a more performant and pragmatic developer experience.
In the playground, you can view the compiled output.
Also, you can change the compile mode, between “Client side rendering”, “Server side rendering”, and “Client side rendering with hydration”
Any code that you write in the playground can be exported to a coding sandbox, like Codesandbox. So helpful!
Philosophy - Think Solid
Declarative Data
Vanishing Components
Solid updates are completely independent of the components. Component functions are called once and then cease to exist.
Read/Write segregation
We don’t need true immutability to enforce unidirectional flow, just the ability to make the conscious decision which consumers may write and which may not.
Simple is better than easy
Compilation
Solid’s JSX compiler doesn’t just compile JSX to JavaScript; it also extracts reactive values (which we’ll get to later in the tutorial) and makes things more efficient along the way.
This is more involved than React’s JSX compiler, but much less involved than something like Svelte’s compiler. Solid’s compiler doesn’t touch your JavaScript, only your JSX.
Destructuring props is usually a bad idea in Solid. Under the hood, Solid uses proxies to hook into props objects to know when a prop is accessed. When we destructure our props object in the function signature, we immediately access the object’s properties and lose reactivity.
So in general, avoid the following:
function Bookshelf({ name }) { return ( <div> <h1>{name}'s Bookshelf</h1> <Books /> <AddBook /> </div> );}
And replace with props instead.
Dependency Arrays
In React, you’d declare the dependencies explicitly using the dependency array. If you didn’t, the effect would rerun whenever any state in the component changes. In Solid, dependencies are tracked automatically, and you don’t have to worry about extra reruns.
Looping with array.map
If we used array.map in Solid, every element inside the book would have to rerender whenever the books signal changes. The For component checks the array when it changes, and only updates the necessary element. It’s the same kind of checking that React’s VDOM rendering system does for us when we use .map.
Conditional if statements on re-rendering
In the Building UI with Components section of this tutorial, we noted that component functions run only once in Solid. This means the JSX returned from that initial function return is the only JSX that will ever be returned from the function.
In Solid, if we want to conditionally display JSX in a component, we need that condition to reside within the returned JSX. While this takes some adjustment when coming from React, we have found that the fine-grained control afforded by Solid’s reactive system is worth the trade-off.
Reactivity and proxy objects
In Solid, props and stores are proxy objects that rely on property access for tracking and reactive updates. Watch out for destructuring or early property access, which can cause these properties to lose reactivity or trigger at the wrong time.
onChange vs. onInput
In React, onChange fires whenever an input field is modified, but this isn’t how onChangeworks natively. In Solid, use onInput to subscribe to each value change.
No VDOM or VDOM APIs
Finally, there is no VDOM so imperative VDOM APIs like React.Children and React.cloneElement have no equivalent in Solid. Instead of creating or modifying DOM elements directly, express your intentions declaratively.
Solid Primitives
Signals - The basic way to manage state in the application
Similar to useState in React, but as a reactive value
Derived state - you can track a computed state from a signal, which is also reactive
You can pass the signal as a prop like this: <BookList books={books()} />. It’s not a typo to use the function as it’s passing an accessor, which is important for reactivity.
Effects - ability to react to signal changes
A driving philosophy of Solid is that, by treating everything as a signal or an effect, we can better reason about our application.
Looping
Solid has a component called <For /> with an each prop. You can pass in a signal that will make this reactive.
As you can see, onInput is the event handler that takes in the event. In this case, we are setting the new book for each input (the title and author).
The onClick handler for the button uses the addBook function where it can prevent the form from submitting, set the books using a new array, then resetting the new book. It should be noted that setBooks is using a callback function where you access the current state. Also, it should be noted not to mutate state by creating that new array (much like in Redux practice).
The primitive for any external data source is createResource. The function returns a deconstructed array with the data. It takes two arguments: the signal and the data fetching function.
Putting it all together, query is the signal. searchBooks is the data fetching function. Once the data is returned, we can loop over it, and for each item, we can set the books if selected.
The following is a code example introducing how Reactivity or Reactive Programming works.
import { createSignal, createEffect } from "solid-js";const [count, setCount] = createSignal(2);const [multipler, setMultiplier] = createSignal(2);const product = () => count() * multipler();// Change the count every secondsetInterval(() => { setCount(count() + 1);}, 1000);// Change the multiplier every 2.5 secondssetInterval(() => { setCount(multipler() + 1);}, 2500);// Effect automatically detects when a signal has changed// So you don't have to add a dependency array.// This is defined as "reactivity"createEffect(() => { console.log(`${count()} * ${multiplier()} = ${product()}`);});
createSignal works by creating a data structure that can read and write. To each of these functions, subscribers are added and updated
CreateEffect works by executing on a context queue (JS array). It takes its queue, executes it, then pops it (at least in pseudocode)
SolidJS uses “granular updates” so only the variables that change only update the DOM, and not entire components.
In this example, we extracted Multipler into its own component, added props, like React, and called it multiple times in App. As you will also notice, signals do not have to be in the function scope! This is counter to what you do in React. Of course, if you don’t want to share the signal across other components, you can keep it in the functional lexical scope.
I started this journey into Typescript by taking a ton of notes with Github Copilot X, “Typescript in 50 Lessons”, and the official documentation. I was able to tailor my experience in understanding how to create types through this method. Without further ado, here’s some notes that I generated (and modified).
What is Typescript?
TypeScript is a superset of JavaScript that adds optional static typing and other features to the language. It is designed to make it easier to write and maintain large-scale JavaScript applications. TypeScript code is compiled into JavaScript code that can run in any browser or JavaScript runtime.
TypeScript provides features such as classes, interfaces, enums, and modules that are not available in standard JavaScript. It also includes support for modern JavaScript features such as async/await and decorators.
TypeScript is developed and maintained by Microsoft, and it is open source and free to use. It is widely used in web development, and many popular frameworks and libraries such as Angular, React, and Vue have TypeScript support.
Static Typing
Static typing in TypeScript allows you to specify the types of variables, function parameters, and return values. This means that you can catch type-related errors at compile-time rather than at runtime.
For example, you can specify that a variable is of type string, and TypeScript will give you an error if you try to assign a number to that variable. Similarly, you can specify that a function takes a parameter of type number, and TypeScript will give you an error if you try to call that function with a string.
Here’s an example of a function that takes two numbers and returns their sum, with static typing:
function addNumbers(x: number, y: number): number { return x + y;}
In this example, the x and y parameters are of type number, and the function returns a value of type number. If you try to call this function with non-numeric arguments, TypeScript will give you an error.
In addition, you can declare types for functions separately to the function implementation. This allows you to define a function type once and reuse it in multiple places.
The void type is used to indicate that a function does not return a value. You can use void as the return type of a function to explicitly indicate that the function does not return anything.
Here’s an example of a function that returns void:
function logMessage(message: string): void { console.log(message);}
In this example, the logMessage function takes a parameter of type string and logs it to the console. The function returns void, which means it does not return a value.
Type Assertions
A type assertion is a way to tell the compiler that you know more about the type of a value than it does. Type assertions are sometimes necessary when working with values that have a more general type than you need.
You can use a type assertion by adding the type you want to assert to the end of an expression, preceded by the as keyword. Here’s an example:
let myValue: any = "hello world";let myLength: number = (myValue as string).length;
In this example, the myValue variable is declared as type any, which means it can hold any value. We then use a type assertion to tell the compiler that we know myValue is actually a string, so we can access its length property.
You can also use angle bracket syntax (< >) to perform a type assertion:
let myValue: any = "hello world";let myLength: number = (<string>myValue).length;
In this example, the type assertion is performed using angle bracket syntax instead of the as keyword.
It’s important to note that type assertions do not change the runtime behavior of your code. They only affect the type checking performed by the TypeScript compiler.
You can use rest parameters to represent an indefinite number of arguments as an array. Rest parameters are denoted by an ellipsis (…) followed by the parameter name.
Here’s an example of a function that uses rest parameters:
function sum(...numbers: number[]): number { return numbers.reduce((total, num) => total + num, 0);}
Primitive Types
There are several primitive types that represent the most basic types of values. These primitive types include:
number: represents numeric values, including integers and floating-point numbers.
string: represents textual values, such as words and sentences.
boolean: represents logical values, either true or false.
null: represents the intentional absence of any object value.
undefined: represents the unintentional absence of any object value.
symbol: represents a unique identifier that can be used as an object property.
let age: number = 30;let name: string = "John";let isStudent: boolean = true;let favoriteColor: string | null = null;let phoneNumber: string | undefined = undefined;let id: symbol = Symbol("id");
Non-primitive types are types that are based on objects rather than simple values. These types include:
object: represents any non-primitive value, including arrays, functions, and objects.
array: represents an ordered list of values of a single type.
function: represents a callable object that can be invoked with arguments.
class: represents a blueprint for creating objects that have properties and methods.
interface: represents a contract that describes the shape of an object.
enum: represents a set of named constants.
Dynamically Generated Types
Dynamically generated types are types that are generated at runtime based on the shape of the data. There are several ways to generate types dynamically in TypeScript:
Index signatures: You can use index signatures to define an object type with dynamic keys. For example:
interface Dictionary<T> { [key: string]: T;}
This interface defines a dictionary type with a dynamic key of type string and a value of type T.
Type assertions: You can use type assertions to cast a value to a specific type at runtime.
const data = JSON.parse(jsonString) as MyType;
This code uses a type assertion to cast the parsed JSON data to a specific type called MyType.
Type guards: You can use type guards to check the type of a value at runtime and conditionally cast it to a specific type. For example:
function isPerson(obj: any): obj is Person { return "name" in obj && "age" in obj;}function printPerson(obj: any) { if (isPerson(obj)) { console.log(`Name: ${obj.name}, Age: ${obj.age}`); } else { console.log("Not a person"); }}
Intersection types: You can use intersection types to combine multiple types into one.
Union Types
A union type is a type that can represent values of multiple types. Union types are denoted by the | symbol between the types.
function printId(id: number | string) { console.log(`ID is ${id}`);}
Union types are useful when you want to write code that can handle multiple types of values.
Intersection Types
An intersection type is a type that combines multiple types into one. Intersection types are denoted by the & symbol between the types.
interface Named { name: string;}interface Loggable { log(): void;}function logName(obj: Named & Loggable) { console.log(`Name is ${obj.name}`); obj.log();}
Intersection types are useful when you want to write code that can handle objects with multiple sets of properties and methods.
Value Types
This interface definition ensures that this Event must have a kind property with one of the three specified values. This can help prevent errors and make the code more self-documenting.
You can use a type guard function to check the type of a value at runtime and conditionally cast it to a specific type. A type guard is a function that returns a boolean value and has a special obj is Type syntax that tells TypeScript that the value is of a specific type.
function isPerson(obj: any): obj is Person { return "name" in obj && "age" in obj;}
You can then use the type guard function to conditionally cast a value to a specific type. Here’s an example:
function printPerson(obj: any) { if (isPerson(obj)) { console.log(`Name: ${obj.name}, Age: ${obj.age}`); } else { console.log("Not a person"); }}
Type Assertions
Type assertions in TypeScript are a way to tell the compiler that you know more about the type of a value than it does. Type assertions are similar to type casting in other languages, but they don’t actually change the type of the value at runtime. Type assertions use the as keyword.
const myValue: any = "hello world";const myLength: number = (myValue as string).length;
This can be useful in JSX format too.
const myComponent = ( <MyComponent prop1={value1} prop2={value2} />) as JSX.Element;
Type Aliases
Type aliases in TypeScript are a way to create a new name for an existing type. They allow you to define a custom name for a type that may be complex or difficult to remember.
Type aliases can also be used with union types, intersection types, and other advanced type constructs. They can help make your code more readable and maintainable by giving complex types a simpler name.
Mapped Types
Mapped types in TypeScript are a way to create new types based on an existing type by transforming each property in the original type in a consistent way. Mapped types use the keyof keyword to iterate over the keys of an object type and apply a transformation to each key.
type Readonly<T> = { readonly [P in keyof T]: T[P];};interface Person { name: string; age: number;}const myPerson: Readonly<Person> = { name: 'John', age: 30 };myPerson.name = 'Jane'; // Error: Cannot assign to 'name' because it is a read-only property.
Mapped types can be used to create many other types, such as Partial, Pick, and Record. They are a powerful feature of TypeScript that can help make your code more expressive and maintainable.
Partial is a mapped type that creates a new type with all properties of the original type set to optional. Here’s an example:
A type predicate in TypeScript is a function that takes an argument and returns a boolean value indicating whether the argument is of a certain type. Type predicates are used to narrow the type of a variable or parameter based on a runtime check.
function isString(value: unknown): value is string { return typeof value === 'string';}function myFunc(value: unknown) { if (isString(value)) { // value is now of type string console.log(value.toUpperCase()); } else { console.log('Not a string'); }}
We define a function myFunc that takes an argument value of type unknown. We then use the isString function to check if value is of type string. If it is, we can safely call the toUpperCase method on value because TypeScript has narrowed the type to string.
never, undefined, null Types
never is a type that represents a value that will never occur. It is used to indicate that a function will not return normally, or that a variable will never have a certain value.
function throwError(message: string): never { throw new Error(message);}
undefined and null are both types and values. The undefined type represents a value that is not defined, while the null type represents a value that is explicitly set to null.
TypeScript also has a --strictNullChecks compiler option that can help prevent null and undefined errors. When this option is enabled, variables that are not explicitly set to null or undefined are considered to be of a non-nullable type. This means that you cannot assign null or undefined to these variables without first checking for their existence.
Classes
Classes in TypeScript are a way to define object-oriented programming (OOP) constructs. They allow you to define a blueprint for creating objects that have properties and methods.
Here’s an example of a class in TypeScript:
class Person { name: string; age: number; constructor(name: string, age: number) { this.name = name; this.age = age; } sayHello() { console.log( `Hello, my name is ${this.name} and I am ${this.age} years old.` ); }}
In this example, the Person class has two properties (name and age) and a method (sayHello). The constructor method is used to initialize the properties when a new object is created.
You can create a new Person object like this:
const person = new Person("Alice", 30);person.sayHello(); // logs "Hello, my name is Alice and I am 30 years old."
One of the main differences between TypeScript and JavaScript classes is that TypeScript allows you to specify the types of class properties, method parameters, and return values. This helps catch type-related errors at compile-time rather than at runtime.
Another difference is that TypeScript provides access modifiers such as public, private, and protected, which allow you to control the visibility of class members. This can help you write more secure and maintainable code.
Finally, TypeScript classes can implement interfaces, which are contracts that describe the shape of an object. This can help enforce type checking on objects that implement the interface.
Access modifiers in TypeScript classes are keywords that determine the visibility of class members (properties and methods). There are three access modifiers in TypeScript:
public: Public members are accessible from anywhere, both inside and outside the class.
private: Private members are only accessible from within the class. They cannot be accessed from outside the class, not even from derived classes.
protected: Protected members are accessible from within the class and from derived classes. They cannot be accessed from outside the class hierarchy.
Here’s an example of a class with access modifiers:
class Person { public name: string; private age: number; protected address: string; constructor(name: string, age: number, address: string) { this.name = name; this.age = age; this.address = address; } public sayHello() { console.log( `Hello, my name is ${this.name} and I am ${this.age} years old.` ); } private getAge() { return this.age; } protected getAddress() { return this.address; }}
In this example, the name property is public, so it can be accessed from anywhere. The age property is private, so it can only be accessed from within the Person class. The address property is protected, so it can be accessed from within the Person class and from derived classes.
Abstract Class
An abstract class is a class that cannot be instantiated directly. Instead, it is meant to be subclassed by other classes that provide concrete implementations of its abstract methods.
An abstract class can have both abstract and non-abstract methods. Abstract methods are declared without an implementation, and must be implemented by any concrete subclass. Non-abstract methods can have an implementation, and can be called by concrete subclasses.
Here’s an example of an abstract class in TypeScript:
abstract class Animal { abstract makeSound(): void; move(distanceInMeters: number) { console.log(`Animal moved ${distanceInMeters}m.`); }}class Dog extends Animal { makeSound() { console.log("Woof! Woof!"); }}const dog = new Dog();dog.makeSound(); // logs "Woof! Woof!"dog.move(10); // logs "Animal moved 10m."
In this example, the Animal class is an abstract class that defines an abstract makeSound method and a non-abstract move method. The Dog class is a concrete subclass of Animal that provides an implementation of the makeSound method. The Dog class can also call the move method inherited from Animal.
But then, what’s the difference between an abstract class and an interface? Take a look at the following example:
In this example, the Animal abstract class and the IAnimal interface both describe objects with a makeSound method and a move method. However, the Animal class is meant to be subclassed, while the IAnimal interface is meant to be implemented.
Some advantages of using inheritance instead of interfaces are:
Multiple Inheritance: An interface can be implemented by multiple classes, while an abstract class can only be subclassed by one class. This can help you create more flexible and reusable code.
Lighter Weight: An interface is a lighter weight construct than an abstract class, since it does not have any implementation details. This can help you write more modular and composable code.
Interfaces
In TypeScript, interfaces are contracts that describe the shape of an object. They define a set of properties and methods that an object must have in order to be considered an implementation of the interface.
Here’s an example of an interface in TypeScript:
interface Person { name: string; age: number; sayHello(): void;}
In this example, the Person interface has two properties (name and age) and a method (sayHello). Any object that implements the Person interface must have these properties and method.
You can use an interface to enforce type checking on objects that implement it. For example, you can define a function that takes a Person object as a parameter:
function greet(person: Person) { person.sayHello();}
In this example, the greet function takes a Person object as a parameter. TypeScript will give you an error if you try to call this function with an object that does not implement the Person interface.
While interfaces and classes have similar ways in defining object types, here are some differences:
Implementation: A class can have both properties and methods, while an interface can only have properties and method signatures. A class is an implementation of an object, while an interface is just a description of an object.
Instantiation: A class can be instantiated to create objects, while an interface cannot. An interface is just a contract that describes the shape of an object.
Inheritance: A class can inherit from another class or multiple classes, while an interface can only extend other interfaces.
Access Modifiers: A class can have access modifiers (public, private, protected) to control the visibility of its members, while an interface cannot.
The benefits of using an interface are the following:
Type checking: Interfaces allow you to enforce type checking on objects that implement them. This can help catch errors at compile-time rather than at runtime.
Code reuse: Interfaces can be used to define a common set of properties and methods that multiple objects can implement. This can help reduce code duplication and make your code more modular.
Abstraction: Interfaces can be used to abstract away implementation details and focus on the contract between objects. This can help make your code more maintainable and easier to reason about.
Polymorphism: Interfaces can be used to create polymorphic behavior, where different objects can be used interchangeably as long as they implement the same interface.
Polymorphism
Polymorphism is the ability of objects to take on multiple forms. In TypeScript, interfaces can be used to create polymorphic behavior, where different objects can be used interchangeably as long as they implement the same interface.
Here’s an example of polymorphism in TypeScript:
interface Shape { getArea(): number;}class Rectangle implements Shape { constructor(private width: number, private height: number) {} getArea() { return this.width * this.height; }}class Circle implements Shape { constructor(private radius: number) {} getArea() { return Math.PI * this.radius ** 2; }}function printArea(shape: Shape) { console.log(`The area of the shape is ${shape.getArea()}`);}const rectangle = new Rectangle(10, 20);const circle = new Circle(5);printArea(rectangle); // logs "The area of the shape is 200"printArea(circle); // logs "The area of the shape is 78.53981633974483"
In this example, the Shape interface defines a getArea method that returns a number. The Rectangle and Circle classes both implement the Shape interface, so they both have a getArea method. The printArea function takes a Shape object as a parameter, so it can be called with either a Rectangle or a Circle object. This is an example of polymorphism, where different objects can be used interchangeably as long as they implement the same interface.
Namespace
In TypeScript, a namespace is a way to group related code into a named scope. Namespaces can contain classes, interfaces, functions, and other code constructs.
You can define a namespace using the namespace keyword, and you can access its contents using the dot notation. Here’s an example:
In this example, the MyNamespace namespace contains an interface Person and a function greet. The Person interface is exported so that it can be used outside of the namespace. The greet function is also exported, and it takes a Person object as an argument.
To use the Person interface and the greet function, you can access them using the dot notation with the namespace name (MyNamespace.Person and MyNamespace.greet).
Enums
In TypeScript, an enum is a way to define a set of named constants. Enums are useful when you have a fixed set of values that a variable can take on, such as the days of the week or the colors of the rainbow.
Here’s an example of an enum in TypeScript:
enum Color { Red, Green, Blue,}let myColor: Color = Color.Red;console.log(myColor); // logs 0
In this example, the Color enum defines three named constants (Red, Green, and Blue). Each constant is assigned a numeric value (0, 1, and 2, respectively) by default. You can also assign string or numeric values explicitly:
enum Color { Red = "#ff0000", Green = "#00ff00", Blue = "#0000ff",}
Generics
Generics in TypeScript allow you to create reusable code components that can work with different types. They provide a way to define functions, classes, and interfaces that can work with a variety of data types, without having to write the same code multiple times.
Here’s an example of a generic function that takes an array of any type and returns the first element:
function getFirstElement<T>(arr: T[]): T { return arr[0];}
In this example, the syntax indicates that the function is generic and can work with any type. The T is a placeholder for the actual type that will be used when the function is called.
The arr parameter is an array of type T, and the function returns a value of type T. When the function is called, the actual type for T is inferred from the type of the array that is passed in.
Generics in TypeScript are commonly used in situations where you want to write code that can work with multiple types. Here are some common use cases for generics:
Collections: Generics can be used to create collections that can hold any type of data. For example, you can create a generic List class that can hold a list of any type of data.
Functions: Generics can be used to create functions that can work with any type of data. For example, you can create a generic identity function that returns its argument of type T.
Interfaces: Generics can be used to create interfaces that can work with any type of data. For example, you can create a generic Comparable interface that defines a method for comparing two objects of type T.
Classes: Generics can be used to create classes that can work with any type of data. For example, you can create a generic Repository class that provides CRUD operations for a data type T.
Modules
In TypeScript, a module is a way to organize code into reusable units. A module can contain classes, functions, interfaces, and other code constructs.
A module can be defined using the export keyword, which makes its contents available for use in other modules. You can also use the import keyword to import code from other modules.
Here’s an example of a module in TypeScript:
// math.tsexport function add(a: number, b: number): number { return a + b;}export function subtract(a: number, b: number): number { return a - b;}
In this example, the math.ts file defines a module that exports two functions (add and subtract). These functions can be imported and used in other modules:
In this example, the app.ts file imports the add and subtract functions from the math module using the import keyword.
Decorators
In TypeScript, a decorator is a special kind of declaration that can be attached to a class declaration, method, accessor, property, or parameter. Decorators use the form @expression, where expression must evaluate to a function that will be called at runtime with information about the decorated declaration.
Decorators can be used to modify the behavior of a class or its members, or to annotate them with additional metadata. For example, you can use a decorator to add logging or validation to a method, or to mark a property as required.
Here’s an example of a decorator in TypeScript:
function log(target: any, key: string, descriptor: PropertyDescriptor) { const originalMethod = descriptor.value; descriptor.value = function (...args: any[]) { console.log(`Calling ${key} with arguments: ${JSON.stringify(args)}`); const result = originalMethod.apply(this, args); console.log(`Result of ${key}: ${JSON.stringify(result)}`); return result; }; return descriptor;}class Calculator { @log add(a: number, b: number) { return a + b; }}const calculator = new Calculator();console.log(calculator.add(1, 2)); // logs "Calling add with arguments: [1,2]" and "Result of add: 3"
In this example, the log function is a decorator that takes three arguments: the target object (the class prototype), the name of the decorated method (add), and a descriptor object that describes the method. The log function modifies the behavior of the method by adding logging statements before and after the original method is called.
The Calculator class has a method add that is decorated with the @log decorator. When the add method is called, the log decorator is executed, which logs the arguments and result of the method.
Similarities can occur on the class level. For example, in this following example, you can write a logger for instantiation.
function log(target: any) { console.log(`Creating instance of ${target.name}`);}@logclass Calculator { add(a: number, b: number) { return a + b; }}const calculator = new Calculator(); // logs "Creating instance of Calculator"console.log(calculator.add(1, 2)); // logs 3
In Astro, there’s this concept of islands. You have a few options on making your page interactive.
From the Astro docs,
these are your options.
---// Example: hydrating framework components in the browser.import DemoApp from "../../components/DemoApp.svelte";---<!-- This component's JS will begin importing when the page loads --><DemoApp client:load /><!-- This component's JS will not be sent to the client untilthe user scrolls down and the component is visible on the page --><DemoApp client:visible /><!-- This component won't render on the server, but will render on the client when the page loads --><DemoApp client:only="svelte" />
I’ll go ahead and try each of these and see what happens.
In the table editor, create a new table messages, and add columns for id, created_at, and content.
id should be a uuid
created_at should default now() and never be null
content is text and should never be null
Setting Up a Remix Project
Create a new remix project
Choose “Just the basics”
Choose Vercel as the service
npx create-remix chatter
For the remix project, you can find the main file in index.tsx
Query Supabase Data with Remix Loaders
npm i @supabase/supabase-js
Add supabase env vars to .env, which can be found in the Project Settings > API. Link
SUPABASE_URL={url}SUPABASE_ANON_KEY={anon_key}
Create a utils/supabase.ts file. Create createClient function
A ”!” can be used at the end of a variable so typescript doesn’t give us errors, if we know those will be available at runtime, like env vars
Supabase has row-level security enabled, meaning you have to write policies in order for the user to do CRUD operations (SELECT, INSERT, UPDATE, DELETE, and ALL).
We added a policy to allow all users to read.
Create the loader in the index page, using import { useLoaderData } from "@remix-run/react";, which will allow us to query supabase using the utils.
supabase.from("messages").select() reminds me a lot like mongodb’s client.
Generate TypeScript Type Definitions with the Supabase CLI
supabase gen types typescript --project-id akhdfxiwrelzhhhofvly > db_types.ts
We have to re-run this command every time we have DB updates
Now we use the db_types.ts into our supabase.ts file by adding a type to the createClient function
You can infer types by using typeof in Typescript. This is useful for showcasing what data’s type is in the Index functional component.
To make sure the data is always present, or an empty array rather than of type null, we use a null coalescing operator on the original data return { messages: data ?? [] };
Implement Authentication for Supabase with OAuth and Github
Enable Github OAuth using Supabase
In the supabase project, go to Authentication > Providers
Choose Github
In Github, go to Settings, Developer Settings > OAuth Apps
Create “Chatter”. Copy the Authorization callback URL
In supabase, enter the Client ID, Client Secret, and the Redirect URL.
The generated secret in Github goes away after a few minutes, so be quick
Create the login component in components/login and then add two buttons for logging in and out.
The handlers should be supabase.auth.signInWithOAuth and supabase.auth.signOut
Add the login component back into the index component.
You’ll notice a ReferenceError in that process is not defined because that should only run on the server.
Change the supabase.ts file to supabase.server.ts file. This shows that the supabase file should only be rendered on the server.
The root.tsx component has an Outlet depending on the route based off the routes files (file-based routing)
In the root component, we add the context in Outlet for the supabase instance.
This can now be used in the login file using useOutletContext.
Types can be added by exporting it from root.
type TypedSupabaseClient = SupabaseClient<Database>;
supabase uses Local Storage to store the OAuth tokens.
You can also check the users in the supabase project
Restrict Access to the Messages Table in a Database with Row Level Security (RLS) Policies
Add a column to our database called user_id and add a foreign key to it, with users and the key being id.
Disable Allow Nullable by adding the logged in user id to the first two messages. This can be found in the users table.
Re-run the db_types script
supabase gen types typescript --project-id akhdfxiwrelzhhhofvly > db_types.ts
Update the policy by changing the target roles to be authenticated.
Now only signed in users will be able to view the data.
Make Cookies the User Session Single Source of Truth with Supabase Auth Helpers
Auth tokens by default are stored in the client’s session, not on the server.
Remix is loading from the server’s session, which is null
npm i @supabase/auth-helpers-remix
We need to change the mechanism for the token to use cookies
Auth helpers allows us to use createServerClient and createBrowserClient to create the supabase instance correctly, based if it’s on the client or server.
You need request and response added in the supabase.server.ts
We need to do the same thing in the loader in root and index
Keep Data in Sync with Mutations Using Active Remix Loader Functions
There’s no update for pressing the button because the client doesn’t update the information after the initial load.
Remix has a revalidation hook.
Supabase has a auth state change hook
Combining these together, on server and client token change (either new token, or no longer has the token), then refetch data from loaders.
Securely Mutate Supabase Data with Remix Actions
To create a new message, we add Form from remix, which has a method post.
This is reminiscent of how forms worked alongside the HTML spec before
An action is created to insert the message, include the response headers from before (passing along the cookie)
The message won’t send yet until the supabase policy is set, so we add a policy for INSERT and make sure the user is authenticated and their user_id matches the one in supabase.
Subscribe to Database Changes with Supabase Realtime
Supabase sends out updates via websockets when there is a change to the database
A feature flag is a decision point in your code that can change the behavior of your application. Feature flags can either be temporary or permanent.
Temporary flags are often used to safely deploy changes to your application or to test new behaviors against old ones. After a new behavior is being used by 100% of your users, the flag is intended to be removed.
Permanent flags give you a way to control the behavior of your application at any time. You might use a permanent flag to create a kill-switch or to reveal functionality only to specific users.
Feature flags are context sensitive. The code path token can change based on the context provided; for example, the user’s identity, the plan they’ve paid for, or any other data.
Feature flags can be used to control which users can see each change. This decouples the act of deploying from the act of releasing.
What do we do today
We have the ability to switch temp flags as kill switch for all customers (new field in result analytics). The permanent flags are controlled per customer (e.g. env mapping). A sub-group of those permanent flags control company integrations with third party services (e.g. Terra).
What are we lacking
What we don’t have is fine control of flags for rollout — using context to switch on/off flags by user, company, or other groups. When introducing new flags, we don’t have a standardized way in storing them in the same place. See companyFeatureToggles vs. companyIntegrations vs. featureFlags. We don’t highlighting flag dependencies. Lastly, permanent flags are limited to a per-company basis.
Definitions
Safety valves are permanent feature flags that you can use to quickly disable or limit nonessential parts of your application to keep the rest of the application healthy.
Kill Switches are permanent feature flags that allows you to quickly turn it off a feature if it’s performing poorly.
Circuit Breakers have the ability to switch off feature flags if they meet certain monitoring criteria.
An Operational Feature Flag are flags around features invisible to customers, such as a new backend improvement or infrastructure change. Operational flags give DevOps teams powerful controls that they can use to improve availability and mitigate risk.
Feature Flag Management Platforms
LaunchDarkly
Split
CloudBees
Deployments
Types of Deployments
There are different types of deployments:
Canary Releases - User groups who would like to opt in
Ring Deployments - Different user segments at a time - e.g. beta or power users
Percentage-based Deployments - Start with low percentage, then move to higher. For operational changes
Each of these can be implemented using feature flags.
Feature flags and blue/green deploys are complementary techniques. Although there are areas of overlap, each approach has distinct benefits, and the best strategy is to use both.
Testing
It isn’t necessary (or even possible) to test every combination of feature flags. Testing each variation of a flag in isolation (using default values for the other flags) is usually enough, unless there’s some known interaction between certain flags.
Library Code
Another decision that affects testing is whether you should use feature flags in reusable library code. I think the answer is no—flags are an application-level concern, not a library concern.
Feature Flag Clean-up
Cleaning up flags aggressively is the key to preventing technical debt from building up. There’s no royal road to flag cleanup, but there are some processes that make it manageable.
A stale flag is a temporary flag that is no longer in use and has not been cleaned up. Too many stale flags are a form of technical debt and an antipattern that you should avoid.
Documentation
Document changes It’s good practice to maintain a log of flag updates. It’s even more helpful to leave a comment with every change. When something is going unexpectedly wrong, being able to quickly see if anything has changed recently (and why it did) is an invaluable asset.
Name your flags well It’s also important to help your team understand what flags are for as easily as possible. So, adopt a naming convention that makes it clear at first glance what a flag is for, what part of the system it affects, and what it does.
Configuration Management
Feature management platforms solve many of these change management problems, but I still do not recommend moving configuration data into feature flags.
Configuration parameters are typically stored in files, environment variables, or services like Consul or Redis. As services become more complex, configuration management becomes a real concern. Tasks like versioning configuration data, rolling back changes, and promoting configuration changes across environments become cumbersome and error prone.
Rather than migrate all configuration data into feature flags, I recommend introducing feature flags selectively on top of whatever configuration management mechanism is in place (files, environment variables, etc.). These flags should be introduced only on an as-needed basis. For example, imagine that you’re trying to manage a database migration via feature flags.
If you had managed your migration by moving the entire database configuration into a feature flag, perhaps by creating a multivariate database-configuration flag, you’d need to keep the flag in place permanently.
Design for Failure
Design multiple layers of redundancy. When you write code you must consider what should happen if the feature flag system fails to respond. Most feature flag APIs include the ability to specify a default option—what is to be served if no other information is available. Ensure that you have a default option and that your defaults are safe and sane.
Flag Distribution via a Networked System
In any networked system there are two methods to distribute information. Polling is the method by which the endpoints (clients or servers) periodically ask for updates. Streaming, the second method, is when the central authority pushes the new values to all the endpoints as they change.
Technique
Pros
Cons
Polling
Simple, Easily Cached
Inefficient. All clients need to connect momentarily, regardless of whether there is a change. Changes require roughly twice the polling interval to propagate to all clients. Because of long polling intervals, the system could create a “split brain” situation, in which both new flag and old flag states exist at the same time.
Streaming
Efficient at scale. Each client receives messages only when necessary. Fast Propagation. Changes can be pushed out to clients in real time.
Requires the central service to maintain connections for every client. Assumes a reliable network.
Relay Proxy
For those customers that have the need for another layer of redundancy on top of the four layers provided by our core service (multiple AWS availability zones, the Fastly CDN, local caching, and default values), we also offer the LaunchDarkly relay proxy (formally known as LD-relay). LD-relay is a small application in a Docker container that can be deployed in your own environment, either in the cloud of your choice or on premise in your datacenter(s).
The Relay Proxy is a small Go application that connects to the LaunchDarkly streaming API and proxies that connection to clients within an organization’s network.
We recommend that customers use the Relay Proxy if they are on an Enterprise plan and primarily use feature flagging in server-side applications. The Relay Proxy adds an additional layer of redundancy in the case of a LaunchDarkly outage.
The following was written for interns starting out with Javascript at Clear Labs.
Base Foundation
Whether this is your first time with Javascript or as a seasoned developer, you should have some base knowledge prior to working with React. While you can learn a framework, it’s more beneficial to understand the language it is written in. For example, what are promises and how does javascript handle asynchronous actions? What is the event loop? And how does Javascript fit in?
Here are some resources to get you started
Freecodecamp - if you have no foundational knowledge of Javascript or need a refresher for the Javascript syntax, start here
MDN Javascript - Mozilla’s documentation on where to get started with Javascript
MDN Promises - Mozilla’s documentation on promises
Async functions - Mozilla’s documentation on handling promises using async functions
Error Handling - Mozilla’s documentation about browser javascript errors
Going Deeper
Many developers find Javascript hard because it started as a scripting language, the syntax looks ugly, and you get these TypeErrors if you’re not careful. That said, with some major changes to the language since Node.js and Google’s V8 engine, Javascript has become a more seasoned programming language. You can develop classes, write generator functions, handle asynchronous events, and enumerate over lists much easier.
Once you’ve started with the basics above, feel free to continue to hone your skills with a deeper understanding of Javascript.
ES2015+ - a new set of functionality in Javascript that allows you to write more effective code. See the Ecmascript section below for more information.
You Don’t Know JS - A series of books written by Kyle Simpson that talks about diving deep into the core mechanisms of Javascript
Ecmascript
JavaScript is a subset of ECMAScript. JavaScript is basically ECMAScript at its core but builds upon it. Languages such as ActionScript, JavaScript, JScript all use ECMAScript as its core. As a comparison, AS/JS/JScript are 3 different cars, but they all use the same engine… each of their exteriors is different though, and there have been several modifications done to each to make it unique.
The history is, Brendan Eich created Mocha which became LiveScript, and later JavaScript. Netscape presented JavaScript to Ecma International, which develops standards and it was renamed to ECMA-262 aka ECMAScript.
It’s important to note that Brendan Eich’s “JavaScript” is not the same JavaScript that is a dialect of ECMAScript. He built the core language which was renamed to ECMAScript, which differs from the JavaScript which browser-vendors implement nowadays.
If your base understanding of Javascript is prior to ES6, you’ll want to read up on the basics. To start, arrow functions, classes, let and const statements are used throughout the app.
Arrow Functions
Often times we have nested functions in which we would like to preserve the context of this from its lexical scope. An example is shown below:
function Person(name) { this.name = name;}Person.prototype.prefixName = function (arr) { return arr.map(function (character) { return this.name + character; // Cannot read property 'name' of undefined });};
One common solution to this problem is to store the context of this using a variable:
function Person(name) { this.name = name;}Person.prototype.prefixName = function (arr) { var that = this; // Store the context of this return arr.map(function (character) { return that.name + character; });};
We can also pass in the proper context of this:
function Person(name) { this.name = name;}Person.prototype.prefixName = function (arr) { return arr.map(function (character) { return this.name + character; }, this);};
As well as bind the context:
function Person(name) { this.name = name;}Person.prototype.prefixName = function (arr) { return arr.map( function (character) { return this.name + character; }.bind(this) );};
Using Arrow Functions, the lexical value of this isn’t shadowed and we can re-write the above as shown:
function Person(name) { this.name = name;}Person.prototype.prefixName = function (arr) { return arr.map((character) => this.name + character);};
Best Practice: Use Arrow Functions whenever you need to preserve the lexical value of this.
Arrow Functions are also more concise when used in function expressions which simply return a value:
Best Practice: Use Arrow Functions in place of function expressions when possible.
Template Literals
Using Template Literals, we can now construct strings that have special characters in them without needing to escape them explicitly.
var text = 'This string contains "double quotes" which are escaped.';let text = `This string contains "double quotes" which don't need to be escaped anymore.`;
Template Literals also support interpolation, which makes the task of concatenating strings and values:
var name = "Tiger";var age = 13;console.log("My cat is named " + name + " and is " + age + " years old.");
Much simpler:
const name = "Tiger";const age = 13;console.log(`My cat is named ${name} and is ${age} years old.`);
In ES5, we handled new lines as follows:
var text = "cat\n" + "dog\n" + "nickelodeon";
Or:
var text = ["cat", "dog", "nickelodeon"].join("\n");
Template Literals will preserve new lines for us without having to explicitly place them in:
let text = `catdognickelodeon`;
Template Literals can accept expressions, as well:
let today = new Date();let text = `The time and date is ${today.toLocaleString()}`;
Classes
Prior to ES6, we implemented Classes by creating a constructor function and adding properties by extending the prototype:
class Personal extends Person { constructor(name, age, gender, occupation, hobby) { super(name, age, gender); this.occupation = occupation; this.hobby = hobby; } incrementAge() { super.incrementAge(); this.age += 20; console.log(this.age); }}
Best Practice: While the syntax for creating classes in ES6 obscures how implementation and prototypes work under the hood, it is a good feature for beginners and allows us to write cleaner code.
Let / Const
Besides var, we now have access to two new identifiers for storing values —let and const. Unlike var, let and const statements are not hoisted to the top of their enclosing scope.
An example of using var:
var snack = "Meow Mix";function getFood(food) { if (food) { var snack = "Friskies"; return snack; } return snack;}getFood(false); // undefined
However, observe what happens when we replace var using let:
let snack = "Meow Mix";function getFood(food) { if (food) { let snack = "Friskies"; return snack; } return snack;}getFood(false); // 'Meow Mix'
This change in behavior highlights that we need to be careful when refactoring legacy code which uses var. Blindly replacing instances of var with let may lead to unexpected behavior.
Note: let and const are block scoped. Therefore, referencing block-scoped identifiers before they are defined will produce a ReferenceError.
console.log(x); // ReferenceError: x is not definedlet x = "hi";
Best Practice: Leave var declarations inside of legacy code to denote that it needs to be carefully refactored. When working on a new codebase, use let for variables that will change their value over time, and const for variables which cannot be reassigned.
Destructuring allows us to extract values from arrays and objects (even deeply nested) and store them in variables with a more convenient syntax.
Destructuring Arrays
var arr = [1, 2, 3, 4];var a = arr[0];var b = arr[1];var c = arr[2];var d = arr[3];let [a, b, c, d] = [1, 2, 3, 4];console.log(a); // 1console.log(b); // 2
Destructuring Objects
var luke = { occupation: "jedi", father: "anakin" };var occupation = luke.occupation; // 'jedi'var father = luke.father; // 'anakin'let luke = { occupation: "jedi", father: "anakin" };let { occupation, father } = luke;console.log(occupation); // 'jedi'console.log(father); // 'anakin'
Parameters
In ES5, we had varying ways to handle functions which needed default values, indefinite arguments, and named parameters. With ES6, we can accomplish all of this and more using more concise syntax.
Default Parameters
function addTwoNumbers(x, y) { x = x || 0; y = y || 0; return x + y;}
In ES6, we can simply supply default values for parameters in a function:
function addTwoNumbers(x = 0, y = 0) { return x + y;}addTwoNumbers(2, 4); // 6addTwoNumbers(2); // 2addTwoNumbers(); // 0
Symbols
Symbols have existed prior to ES6, but now we have a public interface to using them directly. Symbols are immutable and unique and can be used as keys in any hash.
Symbol();
Calling Symbol() or Symbol(description) will create a unique symbol that cannot be looked up globally. A Use case for Symbol() is to patch objects or namespaces from third parties with your own logic, but be confident that you won’t collide with updates to that library. For example, if you wanted to add a method refreshComponent to the React.Component class, and be certain that you didn’t trample a method they add in a later update:
Symbol.for(key) will create a Symbol that is still immutable and unique, but can be looked up globally. Two identical calls to Symbol.for(key) will return the same Symbol instance. NOTE: This is not true for Symbol(description):
A common use case for Symbols, and in particular with Symbol.for(key) is for interoperability. This can be achieved by having your code look for a Symbol member on object arguments from third parties that contain some known interface. For example:
function reader(obj) { const specialRead = Symbol.for("specialRead"); if (obj[specialRead]) { const reader = obj[specialRead](); // do something with reader } else { throw new TypeError("object cannot be read"); }}
A notable example of Symbol use for interoperability is Symbol.iterator which exists on all iterable types in ES6: Arrays, strings, generators, etc. When called as a method it returns an object with an Iterator interface.
Maps is a much needed data structure in JavaScript. Prior to ES6, we created hash maps through objects:
var map = new Object();map[key1] = "value1";map[key2] = "value2";
However, this does not protect us from accidentally overriding functions with specific property names:
> getOwnProperty({ hasOwnProperty: 'Hah, overwritten'}, 'Pwned');> TypeError: Property 'hasOwnProperty' is not a function
Actual Maps allow us to set, get and search for values (and much more).
let map = new Map();> map.set('name', 'david');> map.get('name'); // david> map.has('name'); // true
The most amazing part of Maps is that we are no longer limited to just using strings. We can now use any type as a key, and it will not be type-cast to a string.
Note: Using non-primitive values such as functions or objects won’t work when testing equality using methods such as map.get(). As such, stick to primitive values such as Strings, Booleans and Numbers.
We can also iterate over maps using .entries():
for (let [key, value] of map.entries()) { console.log(key, value);}
Promises
Promises allow us to turn our horizontal code (callback hell):
func1(function (value1) { func2(value1, function (value2) { func3(value2, function (value3) { func4(value3, function (value4) { func5(value4, function (value5) { // Do something with value 5 }); }); }); });});
Into vertical code:
func1(value1) .then(func2) .then(func3) .then(func4) .then(func5, (value5) => { // Do something with value 5 });
Prior to ES6, we used bluebird or Q. Now we have Promises natively:
new Promise((resolve, reject) => reject(new Error("Failed to fulfill Promise"))).catch((reason) => console.log(reason));
Where we have two handlers, resolve (a function called when the Promise is fulfilled) and reject (a function called when the Promise is rejected).
Benefits of Promises: Error Handling using a bunch of nested callbacks can get chaotic. Using Promises, we have a clear path to bubbling errors up and handling them appropriately. Moreover, the value of a Promise after it has been resolved/rejected is immutable - it will never change.
Here is a practical example of using Promises:
var request = require("request");return new Promise((resolve, reject) => { request.get(url, (error, response, body) => { if (body) { resolve(JSON.parse(body)); } else { resolve({}); } });});
We can also parallelize Promises to handle an array of asynchronous operations by using Promise.all():
let urls = [ "/api/commits", "/api/issues/opened", "/api/issues/assigned", "/api/issues/completed", "/api/issues/comments", "/api/pullrequests",];let promises = urls.map((url) => { return new Promise((resolve, reject) => { $.ajax({ url: url }).done((data) => { resolve(data); }); });});Promise.all(promises).then((results) => { // Do something with results of all our promises});
Generators
Similar to how Promises allow us to avoid callback hell, Generators allow us to flatten our code - giving our asynchronous code a synchronous feel. Generators are essentially functions which we can pause their execution and subsequently return the value of an expression.
A simple example of using generators is shown below:
Where next will allow us to push our generator forward and evaluate a new expression. While the above example is extremely contrived, we can utilize Generators to write asynchronous code in a synchronous manner:
// Hiding asynchronousity with Generators
function request(url) { getJSON(url, function (response) { generator.next(response); });}
And here we write a generator function that will return our data:
function* getData() { var entry1 = yield request("https://some_api/item1"); var data1 = JSON.parse(entry1); var entry2 = yield request("https://some_api/item2"); var data2 = JSON.parse(entry2);}
By the power of yield, we are guaranteed that entry1 will have the data needed to be parsed and stored in data1.
While generators allow us to write asynchronous code in a synchronous manner, there is no clear and easy path for error propagation. As such, as we can augment our generator with Promises:
function request(url) { return new Promise((resolve, reject) => { getJSON(url, resolve); });}
And we write a function which will step through our generator using next which in turn will utilize our request method above to yield a Promise:
function iterateGenerator(gen) { var generator = gen(); (function iterate(val) { var ret = generator.next(); if (!ret.done) { ret.value.then(iterate); } })();}
By augmenting our Generator with Promises, we have a clear way of propagating errors through the use of our Promise .catch and reject. To use our newly augmented Generator, it is as simple as before:
iterateGenerator(function* getData() { var entry1 = yield request("https://some_api/item1"); var data1 = JSON.parse(entry1); var entry2 = yield request("https://some_api/item2"); var data2 = JSON.parse(entry2);});
We were able to reuse our implementation to use our Generator as before, which shows their power. While Generators and Promises allow us to write asynchronous code in a synchronous manner while retaining the ability to propagate errors in a nice way, we can actually begin to utilize a simpler construction that provides the same benefits: async-await.
Async Await
While this is actually an upcoming ES2016 feature, async await allows us to perform the same thing we accomplished using Generators and Promises with less effort:
var request = require("request");function getJSON(url) { return new Promise(function (resolve, reject) { request(url, function (error, response, body) { resolve(body); }); });}async function main() { var data = await getJSON(); console.log(data); // NOT undefined!}main();
Under the hood, it performs similarly to Generators. I highly recommend using them over Generators + Promises. A great resource for getting up and running with ES7 and Babel can be found here.
Getter and setter functions
ES6 has started supporting getter and setter functions within classes. Using the following example:
class Employee { constructor(name) { this._name = name; } get name() { if (this._name) { return "Mr. " + this._name.toUpperCase(); } else { return undefined; } } set name(newName) { if (newName == this._name) { console.log("I already have this name."); } else if (newName) { this._name = newName; } else { return false; } }}var emp = new Employee("James Bond");// uses the get method in the backgroundif (emp.name) { console.log(emp.name); // Mr. JAMES BOND}// uses the setter in the backgroundemp.name = "Bond 007";console.log(emp.name); // Mr. BOND 007
Latest browsers are also supporting getter/setter functions in Objects and we can use them for computed properties, adding listeners and preprocessing before setting/getting:
var person = { firstName: "James", lastName: "Bond", get fullName() { console.log("Getting FullName"); return this.firstName + " " + this.lastName; }, set fullName(name) { console.log("Setting FullName"); var words = name.toString().split(" "); this.firstName = words[0] || ""; this.lastName = words[1] || ""; },};person.fullName; // James Bondperson.fullName = "Bond 007";person.fullName; // Bond 007
ES6 Modules
Prior to ES6, we used libraries such as Browserify to create modules on the client-side, and require in Node.js. With ES6, we can now directly use modules of all types (AMD and CommonJS).
Exporting in ES6
With ES6, we have various flavors of exporting. We can perform Named Exports:
export let name = 'David';export let age = 25;
As well as exporting a list of objects:
function sumTwo(a, b) { return a + b;}function sumThree(a, b, c) { return a + b + c;}export { sumTwo, sumThree };
We can also export functions, objects and values (etc.) simply by using the export keyword:
export function sumTwo(a, b) { return a + b;}export function sumThree(a, b, c) { return a + b + c;}
And lastly, we can export default bindings:
function sumTwo(a, b) { return a + b;}function sumThree(a, b, c) { return a + b + c;}let api = { sumTwo, sumThree,};export default api;/* Which is the same as * export { api as default }; */
Best Practices: Always use the export default method at the end of the module. It makes it clear what is being exported, and saves time by having to figure out what name a value was exported as. More so, the common practice in CommonJS modules is to export a single value or object. By sticking to this paradigm, we make our code easily readable and allow ourselves to interpolate between CommonJS and ES6 modules.
Importing in ES6
ES6 provides us with various flavors of importing. We can import an entire file:
import "underscore";
It is important to note that simply importing an entire file will execute all code at the top level of that file.
Similar to Python, we have named imports:
import { sumTwo, sumThree } from "math/addition";
We can also rename the named imports:
import { sumTwo as addTwoNumbers, sumThree as sumThreeNumbers,} from "math/addition";
In addition, we can import all the things (also called namespace import):
import * as util from "math/addition";
Lastly, we can import a list of values from a module:
import * as additionUtil from "math/addition";const { sumTwo, sumThree } = additionUtil;
Importing from the default binding like this:
import api from "math/addition";// Same as: import { default as api } from 'math/addition';
While it is better to keep the exports simple, but we can sometimes mix default import and mixed import if needed. When we are exporting like this:
// foos.jsexport { foo as default, foo1, foo2 };
We can import them like the following:
import foo, { foo1, foo2 } from "foos";
When importing a module exported using commonjs syntax (such as React) we can do:
import React from "react";const { Component, PropTypes } = React;
This can also be simplified further, using:
import React, { Component, PropTypes } from "react";
Note: Values that are exported are bindings, not references. Therefore, changing the binding of a variable in one module will affect the value within the exported module. Avoid changing the public interface of these exported values.
Additional Resources
In addition to those features of ES6+, you’ll notice other features that you can incrementally learn as you go along. Here’s an incomplete list.
The following was written for interns starting out with browsers at Clear Labs.
Javascript was initially developed as a scripting language for the browser. The language has expanded into servers, IoT devices, serverless functions. But let’s take it a step back and talk more about its initial use case with browsers.
Back in the early days of the Web, developers wanted to handle more than reading documents. Forms were introduced to start this interactivity, and soon, developers wanted more APIs. These set of APIs for browsers, known as DOM APIs, became the way a developer could interact with the browser using Javascript. Over the years, this has matured into a large set of APIs.
You can find a separate wiki page for the DOM APIs that we use for our app.
Performance
The DOM, or the document object model, is a representation of the HTML on the page. The browser parses the HTML and puts that HTML in a representation called the DOM. In addition, the browser also parses the CSS and places it in a similar representation known as the CSSDOM. When these two are complete, a paint event can occur which can be shown to the user.
Javascript’s execution is slightly different than HTML and CSS. If Javascript gets loaded prior to the CSSDOM completion, it could block the browser’s paint execution until that Javascript is loaded. This phenomenon, known as Blocking, has some effects on performance.
For a deeper dive into browser performance, here are two (paid) books.
High Performance Web Sites - Written in 2007, still holds value in how browsers run. Some syntax has been updated, but the general advice is sound. It is highly likely you can find this book for free
Even Faster Websites - Written in 2009, a good follow-up to “High Performance Web Sites” that tackles additional topics about Javascript, the Browser, and the Network
To understand blocking, you have to understand the event loop. The following resource is a great primer on the event loop.
What the heck is the event loop anyway? - A Youtube video conference talk on how the event loop works. It also goes over some special topics of multi-threading with Javascript.
Event Handling
One of Javascript’s purposes is to handle events from the user. You could write some code like this:
var input = document.getElementById("input-text-username");input.onchange((event) => { // Do something with the event console.log(event);});
The onchange attribute is function that takes a callback. A callback is a function that gets triggered when the event is triggered. Any event that takes place on the DOM can include a callback, for example, focus in on the element or mouseover the element.
The first number is the MAJOR version. The next is the MINOR version. Last digit is the PATCH version.
Patch Update
In our example table above, react-dates has a patch version update.
21.5.0 -> 21.5.1
The last digit changed from 0 to 1. That means the version is backwards compatible.
Usually this means the package has bug fixes.
You can safely update the package.json with this package without doing any checks.
Minor Update
In our example table above, normalizr has a minor version update.
3.4.1 -> 3.5.0
The second digit changed from 4 to 5. That means the version should be backwards compatible.
Usually this means the package has features added.
You can sometimes safely update the package.json with this package.
Use your intuition if you need to check the pacakage in the app.
For example, if the package type is a dev dependency, most likely you don’t have to make changes.
The example package normalizr would fall under this case, and you can safely upgrade.
If there’s a new API or function worth exploring, make some changes and see how they work, if they apply to our application.
Major Update
In our example table above, babel-jest has a major version update.
24.9.0 -> 25.1.0
The first digit changed from 24 to 25. That means the version is not backwards compatible.
Usually this means the package API has changed.
In some cases, it may be because they have dropped support for an old version of Node. YMMV
You can never safely update the package.json with this package.
Do the following:
Check the CHANGELOG.md or releases Github page. Figure out what the change is
If there are API changes, read up on what the changes are. If they are fundamental and big, do not add. Make a task ticket to upgrade.
Sometimes the library might be popular. They may have a blog post on this. (e.g. Storybook, Apollo, React, and Styled-Components)
If it’s for dropped support for an older version of Node, go ahead and upgrade
For all other changes, upgrade locally, then see if anything in the App breaks. Also check Storybook and tests to see if anything breaks.
Be wary of major changes. When in doubt, as a teammate.
This article was written as part of our initial docs. I have many more articles about React, and I’m debating whether I should cover them in a single article, or multiple. Stay tuned.
At Clear Labs, the web app is a front-end application built on top of React. React is a javascript library that, when paired with other libraries, creates a front-end framework. In our project, we have React on the front-end and nginx serving the assets on the back-end.
If you are starting React with no previous knowledge, please start with the official docs.
Once you have familiarized yourself with the library, play around with it on Codesandbox or on your local system using Create React App. If you can build yourself a basic UI, continue reading this wiki.
Base Foundation
To build with React, each developer should hone their vanilla Javascript knowledge. Please refer to the Javascript wiki to see if you have any missing gaps in your knowledge base.
A must for each developer onboarding is a clear understanding of how React works. This includes the following:
What are React’s lifecycle functions? And how are they supplemented with React hooks?
Why would I use a React class component over a functional component? And when?
This post tries to address these questions and many more.
Newer React Functionality (React v15+)
The application uses many techniques that are worth highlighting because we’ve developer our own set of best practices to follow.
React Context
React Hooks
React Performance APIs (useMemo, useCalllback)
Supporting Libraries
Many supporting libraries help support the development of the app. Most of these supporting libraries are open source and have dedicated wiki pages. Here are the highlights:
React-Final-Form
Downshift
d3
i18next
Luxon (migrating from moment)
Components
Our project includes Storybook, an interactive UI tool to develop and document components. In each component, an extra js file is created with the stories suffix. E.g. index.stories.js. This helps with developing components on their own and reduces overhead with creating component properties.
Refactoring class components to functional components
Lifecycle functions can be replaced with useEffect. But be careful, as we mentioned in useEffect vs useLayoutEffect, useEffect is asynchronous and lifecycle functions aren’t a 1
match.
componentDidMount() {// do something}// now becomesuseEffect(() => {// do something}, []);
Building Components
While the previous section introduced us to components, this section expands on how we write components.
Class or Function?
When creating a new component, start off with a function component. What is a function component?
const FunctionComponent = (props) => <div>Here's the JSX</div>;
A function component is an easier markup to read. To React, a function component vs. a class are indistinguishable. As developers, we aim for clean code. Ask yourself the following questions of whether you might need a class.
Do we need lifecycle functions? If this is yes, evaluate whether you can use Hooks instead. If not, use a class.
Do we need a constructor? Rarely do we need a constructor. If you need one ask what special cases are you doing to state or what the justification is for other constructor needs.
Does the component need private or public methods? On a rare occassion, we may want to expose a public class method. Use a class.
Maybe there are private methods a class should have. Use a class.
In general, for most components are function components. With the introduction of hooks, function components can also have state. We have our own section about hooks too.
Component or PureComponent?
If using a class, we can further ask whether a PureComponent should be extended vs. a Component.
Compound Components
Compound components allow you to create and use components which share this state implicitly.
Other Related Articles
I’ve written a few other React articles, as shown below:
The following guide is a modified version that we use at Clear Labs dev team. It’s a starting point for team dev work and contribution.
When contributing to this repository, please first make sure a ticket is filed for the change, whichever ticketing system is used.
At Clear Labs, we use JIRA, but the same can be done for Github issues, or any other ticketing system.
Please note we have a code of conduct. Please follow it in all your interactions with the project.
How To Contribute
When beginning development, you will need to create a git branch. See Git Branches
for more information about naming your git branch.
Git Branches
The app has three main branches.
develop ➡ Maps to the Development environment
main ➡ Maps to the Production environment
release ➡ Maps to the released versions on the Production environment (we have slow release cycles, )
In development, a developer will create a feature branch, named after a ticket number, e.g. ENG-2120.
When the ticket is ready to test, the develop will create a pull request (PR) against the develop branch.
When a set of features are completed, a PR will be created between the develop branch and the master branch.
Before the PR is merged, the developer needs to tag the develop branch with the proper version tag.
QA will approve this PR when they are ready to upgrade the QA environment with the developer’s latest changes.
When a set of features are tested, a develop needs to create a PR between the main and release branch.
When QA approves this PR, the developer will tag and merge this PR.
Naming Scheme for CI
Name your branches with these prefixes. This will test and build the application in our CI.
ENG-*
hotfix-*
feature-*
Commits
All commits need to contain a ticket number. If a commit does not contain a ticket number, the push to Bitbucket will not be allowed.
Example:
git commit -m “ENG-2120 resolve breaking change from GraphQL API for test runs”
In case a commit does not contain a ticket number, you have a few strategies to resolve this:
rebase against develop. git rebase develop -i
if it is the latest commit, you can amend it. git commit --amend
Pull Request Process
Ensure any install or build dependencies are removed before the end of the layer when doing a build. Please use the .gitignore file for ignoring unnecessary files. Make sure all commit messages have a JIRA ticket tag. e.g. git commit -m "ENG-100 commit message"
Update the README.md with details of changes to the interface, this includes new environment variables, exposed ports, useful file locations and container parameters. If there are changes to development, please update the development guide.
If creating a PR to master branch, tag the develop branch with a bump in the version. The same goes for a PR to release by tagging main. For develop ➡ main branch, take the base version, add a hyphen, and concat the date (mm/dd) plus an incrementor. e.g. v1.6.0.0.1-Feb.01.1 For master ➡ release-candidate branch, give the version. e.g. v1.6.1. For additional information about versioning, please refer to the next section.
JIRA should add a list of commits going into this PR. If not, please add them with the JIRA ticket tag.
You may merge the Pull Request in once you have the sign-off of one other developer, or if you do not have permission to do that, you may request the second reviewer to merge it for you.
Preleases are used for git tagging between develop and master branches. This is denoted by an alpha-{number}, e.g. v0.9.13.alpha-1
Releases are versioned without prerelease words, e.g. v0.9.13
For hotfixes, bump the patch version. e.g. v0.9.13 -> v0.9.14
Upon later inspection, we no longer use prereleases.
🚨 Deprecation Notice
Moving forward, release-candidate will be deprecated in favor of using main without release.
Code of Conduct
Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, gender identity and expression, level of experience,
nationality, personal appearance, race, religion, or sexual identity and
orientation.
Our Standards
Examples of behavior that contributes to creating a positive environment
include:
Using welcoming and inclusive language
Being respectful of differing viewpoints and experiences
Gracefully accepting constructive criticism
Focusing on what is best for the community
Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
The use of sexualized language or imagery and unwelcome sexual attention or advances
Trolling, insulting/derogatory comments, and personal or political attacks
Public or private harassment
Publishing others’ private information, such as a physical or electronic address, without explicit permission
Other conduct which could reasonably be considered inappropriate in a professional setting
Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the Engineering Manager. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project’s leadership.
These notes are a guide I’ve written throughout coding the initial part of the application. The note starts out with fundamentals and continues with specific testing edge cases.
Philosophy
Write tests. Not too many. Mostly integration.
Guillermo Rauch
The more your tests resemble the way your software is used, the more confidence they can give you.
Kent C. Dodds
This project focuses mainly on integration tests. Why? We shouldn’t mock too much as the tests themselves become unmaintainable.
When you make any changes to the code with tests that have a lot of mocking, the tests also have to be updated.
Mostly manual. And we end up creating more work for the developer than is actually worth.
Code coverage also isn’t the best factor to aim for. Yes, we should have tests to cover our code. No, we shouldn’t aim for 100% coverage.
Pareto’s law can apply here. For most cases, we expect few test to cover most use cases. At some point, there’s diminishing returns.
Out of the box, the testing framework and its tools are installed with dependencies.
For more information, checkout the installation section of the README.
Unit tests are run before a building the Docker container.
Tests are run with Jest, that has the Expect expectations library given.
As mentioned in the testing philosophy, we try not to focus on mocking. Sometimes this is inevitable and we have included Enzyme for shallow rendering.
Use shallow sparingly. For more, read this article.
yarn test
Additional Commands
If there are any jest flags you want to add to your tests, like watch mode or coverage, you can add those flags to the command.
Watch
# Run tests in watch modeyarn test --watch
Coverage
# Run a coverage reportyarn test --coverage# This will build a `coverage` folder that can be viewed for a full coverage report
Single file or folder
# Run tests over a single fileyarn test src/path/to/file# Run tests over a folderyarn test src/path/to/folder
State Management Testing
Test all actions, sagas, and reducers.
Action tests are ensuring the action creators create the proper actions
Reducer tests are ensuring the state has been changed properly
Saga tests are more for E2E testing, making sure all side-effects are accounted for
Move data fetching code or side effects to componentDidUpdate.
If you’re updating state whenever props change, refactor your code to use memoization techniques or move it to static getDerivedStateFromProps. Learn more at: https://fb.me/react-derived-state
Rename componentWillReceiveProps to UNSAFEcomponentWillReceiveProps to suppress this warning in non-strict mode. In React 17.x, only the UNSAFE name will work. To rename all deprecated lifecycles to their new names, you can run npx react-codemod rename-unsafe-lifecycles in your project source folder.
Please update the following components: *
With a move to React v16.8 -> v16.9, componentWillMount, componentWillReceiveProps, and componentWillUpdate lifecycle methods have been renamed.
They will be deemed unsafe to use. Our library has updated already, but some libraries may still use this.
Known libraries with issues:
react-dates
react-outside-click-handler (dev dependency to react-dates)
Invariant Violation: Could not find “store” in the context of “Connect(Form(Form))”.
Either wrap the root component in a “Provider”, or pass a custom React context provider
to “Provider” and the corresponding React context consumer to Connect(Form(Form))
in connect options.
Solution
Add imports
import { Provider } from "react-redux";import configureStore from "redux-mock-store";
Create the mock store. Wrap renderer with provider.
You’ve included redux in your test, but you might get the following message.
[redux-saga-thunk] There is no thunk state on reducer
If this is the case, go back to your mock store and include thunk has a key.
it("renders a component that needs to thunk", () => { const mockStore = configureStore(); const store = mockStore({ thunk: {} }); // Be sure to include this line with the thunking const tree = renderer .create( <Provider store={store}> <TestedComponent /> </Provider> ) .toJSON(); expect(tree).toMatchSnapshot();});
i18n Error
Sometimes, an i18n provider isn’t given. The error doesn’t appear to be useful.
TypeError: Cannot read property ‘ready’ of null
Check if the component or a child component uses the Translation component. If so, Translation requires context Provider be wrapped around.
Solution
Add imports
import { I18nextProvider } from "react-i18next";import i18n from "../../../test-utils/i18n-test";
Rerun the test and check the snapshot. If the snapshot looks good, add the -u flag to update the snapshot.
Apollo Error
If the component requires an apollo component, you will want to pass in a mock provider.
Invariant Violation: Could not find “client” in the context or passed in as a prop.
Wrap the root component in an “ApolloProvider”, or pass an ApolloClient instance in via props.
Add imports
import { MockedProvider } from "@apollo/client/testing";
TypeError: Cannot read property ‘createLTR’ of undefined
Solution
Solve by adding the following to the top of the test file
import "react-dates/initialize";
As of v13.0.0 of react-dates, this project relies on react-with-styles. If you want to continue using CSS stylesheets and classes, there is a little bit of extra set-up required to get things going. As such, you need to import react-dates/initialize to set up class names on our components. This import should go at the top of your application as you won’t be able to import any react-dates components without it.
Final Form
Warning: Field must be used inside of a ReactFinalForm component
When you use the test renderer, this won’t work.
For an exhaustive way of triggering events, check out
this post.
The preliminary solution is to run act from the react-test-renderer library.
Currently, there is no documentation to this, so it’s best to
read the code.
Here’s how we use act.
it("creates component with useEffect", () => { // Create your tree const tree = renderer.create( <TestComponentWithEffect>My Effect</TestComponentWithEffect> ); // Tell the renderer to act, pushing the effect through renderer.act(() => {}); expect(tree.toJSON()).toMatchSnapshot();});// Drawbacks:// - Can't handle flushing (yet)
This will be revisited as the API matures.
Dealing with Time
If you need to mock time, you could use this implementation.
const constantDate = new Date("2019-05-16T04:00:00");/* eslint no-global-assign:off */Date = class extends Date { constructor() { super(); return constantDate; }};
At my new job, because we’re building the project from the ground up. The team decided to move forward with a css-in-js approach, which perked my ears. First I was skeptic. How could this remove my css files? What about psuedoelements and complex selectors.
Having worked with it for three months now, I’m a convert. Those initial skepticisms wore away as I started to write React with styled components in mind. Before I jump into a length explanation, let’s do a starter demo.
Intoduction through exercise
import React from "react";import styled from "styled-components";const Wrapper = styled.div` padding: 1rem;`;const MainContent = styled.div` font-size: 1.2rem; text-align: center;`;const App = (props) => ( <Wrapper {...props}> <MainContent> Lorem ipsum dolor sit amet, vim at quando possim oporteat, eu omnium apeirian argumentum per. </MainContent> </Wrapper>);
Brace expansion is used to generate arbitrary strings. The specified strings are used to generate all possible combinations with the optional surrounding preambles and postscripts.
Usually it’s used to generate mass-arguments for a command, that follow a specific naming-scheme.
:!: It is the very first step in expansion-handling, it’s important to understand that. When you use
echo {a,b}$PATH
then the brace expansion does not expand the variable - this is done in a later step. Brace expansion just makes it being:
echo a$PATH b$PATH
Another common pitfall is to assume that a range like ”{1..200}” can be expressed with variables using ”{$a..$b}”. Due to what I described above, it simply is not possible, because it’s the very first step in doing expansions. A possible way to achieve this, if you really can’t handle this in another way, is using the ”eval” command, which basically evaluates a commandline twice: eval echo {$a..$b} For instance, when embedded inside a for loop : for i in $(eval echo {$a..$b}) This requires that the entire command be properly escaped to avoid unexpected expansions. If the sequence expansion is to be assigned to an array, another method is possible using declaration commands: declare -a 'pics=(img{'"$a..$b"'}.png)'; mv "${pics[@]}" ../imgs This is significantly safer, but one must still be careful to control the values of $a and $b. Both the exact quoting, and explicitly including “-a” are important.
The brace expansion is present in two basic forms, string lists and ranges.
It can be switched on and off under runtime by using the ”set” builtin and the option ”-B” and ”+B” or the long option ”braceexpand”. If brace expansion is enabled, the stringlist in ”SHELLOPTIONS” contains ”braceexpand”.
String lists
{string1,string2,...,stringN}
Without the optional preamble and postscript strings, the result is just a space-separated list of the given strings:
$ echo {I,want,my,money,back}I want my money back
With preamble or postscript strings, the result is a space-separated list of all possible combinations of preamble, specified strings and postscript:
The brace expansion is only performed, if the given string list is really a list of strings, i.e. if there’s minimum one ””,”” (comma)! Something like ”{money}” doesn’t expand to something special, it’s really only the text ””{money}””.
Ranges
{<START>..<END>}
Brace expansion using ranges is written giving the startpoint and the endpoint of the range. This is a “sequence expression”. The sequences can be of two types
integers (optionally zero padded, optionally with a given increment)
characters
$ echo {5..12}5 6 7 8 9 10 11 12$ echo {c..k}c d e f g h i j k
When you mix these both types, brace expansion is not performed:
$ echo {5..k}{5..k}
When you zeropad one of the numbers (or both) in a range, then the generated range is zeropadded, too:
$ echo {01..10}01 02 03 04 05 06 07 08 09 10
There’s a chapter of Bash 4 brace expansion changes at [[#new_in_bash_4.0 | the end of this article]].
Similar to the expansion using stringlists, you can add preamble and postscript strings:
When you combine more brace expansions, you effectively use a brace expansion as preamble or postscribt for another one. Let’s generate all possible combinations of uppercase letters and digits:
Brace expansions can be nested, but too much of it usually makes you losing overview a bit ;-)
Here’s a sample to generate the alphabet, first the uppercase letters, then the lowercase ones:
{% assign special = '{{A..Z},{a..z}}' %}$ echo {{ special }}A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z
Common use and examples
Massdownload from the Web
In this example, ”wget” is used to download documentation that is split over several numbered webpages.
”wget” won’t see your braces. It will see 6 different URLs to download.
See the [[#news_in_bash_4.0 | text below]] for a new Bash 4 method.
Repeating arguments or words
somecommand -v -v -v -v -v
Can be written as
somecommand -v{,,,,}
…which is a kind of a hack, but hey, it works.
More fun
The most optimal possible brace expansion to expand n arguments of course consists of n’s prime factors. We can use the “factor” program bundled with GNU coreutils to emit a brace expansion that will expand any number of arguments.
function braceify { [[ $1 == +([[:digit:]]) ]] || return typeset -a a read -ra a < <(factor "$1") eval "echo $(printf '{$(printf ,%%.s {1..%s})}' "${a[@]:1}")"}printf 'eval printf "$arg"%s' "$(braceify 1000000)"
“Braceify” generates the expansion code itself. In this example we inject that output into a template which displays the most terse brace expansion code that would expand ”“$arg”” 1,000,000 times if evaluated. In this case, the output is:
After reading a lengthy comic from Lin Clark about WebAssembly,
I thought it might be great to do a deep dive with it.
Thank goodness the folks behind the project have a very nice Getting Started tutorial.
Prerequisites
To compile to WebAssembly, we will at the moment need to compile LLVM from source. The following tools are needed as a prerequisite:
I’m on OSX. Check the link for above for your prerequisites.
Git
CMake
Xcode
Python (2.7.x)
Compile Emscripten from Source
Building Emscripten from source is automated via the Emscripten SDK. The required steps are as follows.
After these steps, the installation is complete. To enter an Emscripten compiler environment in the current command line prompt, type
$ source ./emsdk_env.sh
This command adds relevant environment variables and directory entries to PATH to set up the current terminal for easy access to the compiler tools.
Note, the installation process will take a while. Go make yourself some tea.
To conveniently access the selected set of tools from the command line,consider adding the following directories to PATH, or call 'source./emsdk_env.sh' to do this for you.
Compile and run a simple program
We now have a full toolchain we can use to compile a simple program to WebAssembly. There are a few remaining caveats, however:
We have to pass the linker flag -s WASM=1 to emcc (otherwise by default emcc will emit asm.js).
If we want Emscripten to generate an HTML page that runs our program, in addition to the wasm binary and JavaScript wrapper, we have to specify an output filename with a .html extension.
Finally, to actually run the program, we cannot simply open the HTML file in a web browser because cross-origin requests are not supported for the file protocol scheme. We have to actually serve the output files over HTTP.
The commands below will create a simple “hello world” program and compile it. The compilation step is highlighted in bold.
To serve the compiled files over HTTP, we can use the emrun web server provided with the Emscripten SDK:
$ emrun --no_browser --port 8080 .
Once the HTTP server is running, you can open it in your browser. If you see “Hello, world!” printed to the Emscripten console, then congratulations! You’ve successfully compiled to WebAssembly!
Here’s how my logs looked when running the program
➜ hello-wasm emcc hello.c -s WASM=1 -o hello.htmlINFO:root:generating system library: libc.bc... (this will be cached in "/Users/Jeremy/.emscripten_cache/asmjs/libc.bc" for subsequent builds)INFO:root: - okINFO:root:generating system library: dlmalloc.bc... (this will be cached in "/Users/Jeremy/.emscripten_cache/asmjs/dlmalloc.bc" for subsequent builds)INFO:root: - okINFO:root:generating system library: wasm-libc.bc... (this will be cached in "/Users/Jeremy/.emscripten_cache/asmjs/wasm-libc.bc" for subsequent builds)INFO:root: - ok
A friend asked for my help with an upcoming interview she’s preparing for,
so I thought it’s a good time to write-up the interview preparation process.
Interview Help Request
The following is the initial exchange of what areas she wanted to focus on.
Here are the areas and key points (I know of) that they will be asking me about during the interview.
For some additional context, the interview itself will have the interviewers seated and me standing in front of a whiteboard I can use when I am trying to explain a concept as well.
Definitely meant to help them get a feel for how a candidate would present the information to a group of students.
1. Explaining the HTTP Request and Response Cycle
This is what [the interviewers] like to start with.
I should be able to comfortably navigate through the [HTTP Request & Response] cycle at its simplest.
[For example, explain a GET request].
Accurately describe major components:
HTTP
DNS
the Client & Server
HTTP request and response anatomy
[And] note possible variations of a particular step.
For example, naming a few common HTTP request and/or response headers that may be included and why.
You must mention when & how a set-session token/key fits into this.
Not sure whether or not I will need to get into the difference between handling a request for static content vs. a request requiring server-side processing.
[They may want me to cover] server-side processing in the next topic.
Additionally, I wouldn’t be surprised if they wanted to test my general knowledge of the server setup.
I would probably touch on this in my explanation, however they may want me to further clarify the role of the load balancer/proxy server software
we typically install during deployment, such as Nginx/Phusion Passenger, and how its role differs from the server where the actual application/site resides.
Or, just throw out a question to test that I know what it is.
While listening to my presentation they will be making sure that I properly refer to the different parts and how they relate to each other.
Interviewers are likely to interject asking for clarification on a point I glossed over, or if they want to see whether I have further knowledge of a component mentioned.
From what I was told they try to make some questions somewhat similar to how a student may probe a new teacher during a lecture.
2. Explaining MVC pattern architecture
I wasn’t asked this in the first interview, however know I will be asked about this on the second.
I am not sure exactly about the depth they will want me to go into. I think it mainly pertains to my understanding purpose of this architecture as well as being able to explain what each component/part does and how they interact.
Finally, they will probably want my presentation to touch on request handling within an MVC pattern framework as well, definitely heard the motto “fat models, skinny controllers” a lot when I was being taught.
I think they want me to be able to provide a good 1-3 sentence definition of each of the three pillars. They will likely ask me to define some basic components and throw in trivial questions regarding classes, objects, method overriding, etc.
In addition to above, they may want me to write out an example of one or possibly all the 3 pillars in Python/Ruby. (for this specific position, they will likely want some verbal/written examples to be provided for most of the topics mentioned)
4. REST APIs & RESTful Routing
These areas I am more unsure about, in regards to what kind of information they would want.
We didn’t go very deeply into the concept of REST APIs during the bootcamp itself, any explanations were usually in optional sections of the platform.
My best guess, based on the curriculum, is they would be satisfied with a well-rounded-sm overview/definition of what REST is and why its used.
Additionally, explaining implementation of RESTful Routing in a framework such as Rails or Django (more semi-RESTful for the latter).
And there is a small chance they may ask me about APIs, which can be as general as “What is an API?” and “How are they used?” or as specific as providing an example of API usage with AJAX and jQuery.
5. JavaScript Algorithms
There is a 75% chance they will ask me to do up to 2 of the following,
however depending on the interviewer there is an off-chance I can get an algorithm I have never seen before or one they know I can’t solve.
Basic Data-type Manipulation (strings/arrays/dictionaries) - eg; reversing an array in place
Popular Sorting Algorithms (Bubble, Selection, Insertion or Merge). most likely culprits, but Quick Sort is on the table as well
Algorithms using Linked Lists or Binary Search Tree data structures. Could be Push/Shift/Unshift/Pop methods, linked lists algorithms & find/search with a BST
Based on the advice I was given, they would first want me to explain how a particular algorithm works/show I understand the objective (eg, that the Push method would mean adding a node to the end of the linked list in question, or that I can explain how the Bubble sort actually sorts an array rather than how the Selection sort would accomplish that), next psuedo-code and say how I plan to approach the solution, then writing out the code (last two parts can be combined, like explaining as I write out the code).
Sample Questions
From this scope, I’m taking a stab at formulating questions I would ask if I was interviewing this candidate.
Questions about HTTP Request & Response Cycle
Explain what happens when a user hits enter after typing a URL in a browser.
What is the difference between latency and bandwidth?
What is DNS?
What is an IP address?
Explain the HTTP request & response cycle
Explain an AJAX request
What are the drawbacks of using cookies? What are alternatives?
What is session management?
Networking Questions
What would you check if a website is slow?
What is a load balancer? What are some examples of solutions?
What are some ways to optimize the payload sent from the server? (For example, gzip, uglfying js, minimizing css/js, shortening header content length, etc.)
What is a CDN?
Security Questions
What is CORS? What can you do with CORS to secure your website from cross-site request forgery (CSRF)?
Questions about MVC Model
What is the MVC model?
How does the model, controller, and view interact with each other in Django?
How about in Rails? How about in any front-end framework?
Have you heard of variations on the MVC model, like MVVM or MVP?
stackoverflow
What are some examples of frameworks with MVC on the back-end?
What are some examples of having MVC or MVC-like frameworks on the front-end?
What are the pros and cons of having MVC all on the back-end?
Extra database questions
What is ORM?
What is a Store Procedure and how is it different to ORM?
Can you write SQL queries in Rails Active Record?
What is NoSQL?
Why use a Document Database over a Relational Database?
What are some purposes of a key-value store like Redis?
Why use placeholders in SQL queries? (Answer: defense against SQL Injections)
Better Question: What is a placeholder and why would you use them in SQL queries?
Questions about JavaScript Algorithms
Write a function that receives an argument for prime # and return the prime in that position.
Example:
getPrime(2); // 3getPrime(5); // 11
Given a nested array, [1, [2, 3, [4]], flatten the array, [1, 2, 3, 4].
In recursion, what is a base condition?
Without using Javascript’s map function, please write your own map implementation.
Write a select function that takes an array of objects and finds the first entry of the object with a given name.
Given an array from 1 to 100, write a binary search which takes a target. What is the O notation of your solution?
(I personally hate this question)
Given a class that mimics linked list data structure, write an add function for it.
(I also hate this question)
Write a function that is a closure, i.e. a function that returns a function, for adding.
The input is how much to add by.
The return is a function that takes a number input that returns the sum of that number
and the first input.
Write a debounce function.
Debouncing is when you stop firing the same function for a certain amount of period after firing for the the first time.
For example, if you had a “resize” function, you would not fire “resize” if you set the debounce for 500ms.
What is the purpose of this keyword in Javascript?
Explain scoping in Javascript.
Explain variable hoisting in Javascript.
Given a list of U.S. states and a list of capital cities, how would you merge these two lists to return one list?
The common factor between these two are state codes.
State collection example entry:
Follow-up: How could you filter this so you only return states that start with “North” or “South”?
Could you do this using the reduce function for Javascript Arrays?
What is a cache and how would you write a simple key-value cache?
What is a lambda and why use this over blocks? How are lambdas and closures related?
What are the differences between private and protected methods?
Other Questions
What is your favorite open source framework? Why is it your favorite? Are you a contributor to that project?
What are the pros and cons of choosing an open source framework over a custom solution? When is it valid for a custom solution?
What are some principles you have to error handling?
Follow-up: What are some common exception types?
Why would you use a try...catch block and should you use this in production?
What are some general use-cases for logging?
What are common failures that would cause your server to crash?
Sample Criteria
Here’s some criteria I look at when interviewing a new candidate. This is from past experience.
Knowledgable: Can the candidate explain the content? Can the candidate solve the whiteboard problem? Can the candidate explain their own code? Can the candidate explain a foreign topic? (BS monitor)
Presentation: Is the candidate concise? Or do they ramble? Can they explain concepts in a minute or less? Do they gauge the interviewer for comprehension? Is the candidate audible?
Personality: Is the candidate asking questions and are they probing on open ended questions? Does the candidate exude humility, like saying “they don’t know” when they don’t know something?
Seriousness: Is the candidate serious about the position? Did they do any research prior?
Team player: Is the candidate’s prior work long-standing at a single company or jumping around a lot in short-term gigs? Can the candidate work well with others?
The Javascript ES2015 spec introduces object destructing. Object destructing used to pass a single object parameter instead of long argument lists to functions. Take the following code example.
Bad Code:
function enableListFilter(option, filterName, filterIndex, activeAccessTypeIndex) { // Do Something}enableListFilter(option, filterName, filterIndex, activeAccessTypeIndex);
The function requires the developer to know the order of the parameters passed into the function.
When this is one argument, that’s easy.
When it gets to 2 or more arguments, this can get difficult since that stretches a developer’s working memory a la “yet another thing to remember”.
Here’s an alternative.
Better Code:
function enableListFilter({ option, filterName, filterIndex, activeAccessTypeIndex }) { // Do Something}enableListFilter({ option: option, filterName: filterName, filterIndex: filterIndex, activeAccessTypeIndex: activeAccessTypeIndex});
If you want to reduce the number of lines, you can use the object parameter shorthand.
Note: A caveat of this approach your argument names must be the same name.
In most cases, an explicit approach of writing out object keys is better.
I’ve been a Javascript developer for the past year and a half. By reading the “You don’t Know Javascript” series, I’m hoping to hone my vanilla Javascript skills and have a deeper knowledge of the language.
In Up & Going, I’m hoping to review the basics and understand more deeply why the language has the set of tools it has, and perhaps a deeper understanding of why we write Javascript the way we do.
When you strive to comprehend your code, you create better work and become better at what you do.
Preface
This You Don’t Know JavaScript book series offers a contrary challenge: learn and deeply understand all of JavaScript, even and especially “The Tough Parts”.
I like this attitude as it focuses on the bits of the language I have to deal with time and time again. It helps me understand the behavior of Javascript without blindly looking at a TypeError with a quizzical expression.
i.e. Cut out the buzzwords. Learn the language
Chapter 1: Into Programming
Explains programming at a high level. I may skip large sections of this.
literal value are values that are itself and are not stored. e.g. in the statement, y = x + 4;, 4 is a literal value.
Expressions are the reference to variables, values, or set of variable(s) and value(s) combined with operators.
Assignment expressions assign a variable to another expression
I’m reviewing this because these basic building blocks can be fundamentally different. In Go, assignments can be completely different
Review later: Javascript compiling in the first two chapters of Scope & Closures
The prompt() function opens an alert with an input. You can assign the function with a variable. age = prompt("What is your age?");
We take it for granted that specifying the variable in an assignment is typically on the left.
Side tangent: Are there languages that do the opposite?
Some lesser known assignments in JS include
Remainder assignment x %= y
Shift assignments x <<= y
Shift bits left or right by a certain amount. The above example shifts bits to the left.
Bitwise assignments x &= y or x = x & y
The above example pertains to bits, using an AND logic.
AND logic table
Bit
Bit
Result
0
0
0
1
0
0
0
1
0
1
1
1
values added to the source code are called literals
Implicit coersion is when you’re making a comparison against two different types. The == operation is ‘loosely equal’ and uses implicit coersion. For this reason, it should be avoided because it can cause unexpected bugs.
More on this later in Chapter 2 of this title & Chapter 4 of Types & Grammar
Code comments help other humans understand your code. It’s a communication point.
Comments should explain why, not what. They can optionally explain how if that’s particularly confusing.
Note to self - focus on why, and less on what.
Static Typing - variables adhere to type enforcement
Dynamic Typing - allows a variable to represent a value regardless of type. Javascript adheres to this.
State is tracking changes to values as the program runs. In redux, we keep a global state to track the user’s progress through the application.
Constants are declared once and don’t change. In ES6, when you declare a constant once, it throws an error if there is an attempt to change it. This is like the static-tying type enforcement.
A group of series of statements strung together are called a block. A block is contained within curly brackets. { .. }
In Ruby, there are different ways to show a block. In fact, there are different types of blocks, like your general block, procs, and lambdas.
Conditions throw an error if its expression between the parentheses are not a boolean.
“Falsy” values are converted to the boolean false. “Truthy” values do the opposite. More on this in Chapter 4 of Types & Grammar
An iteration occurs each time a block is called.
Warning: For a variety of historical reasons, programming languages almost always count things in a zero-based fashion, meaning starting with 0 instead of 1. If you’re not familiar with that mode of thinking, it can be quite confusing at first. Take some time to practice counting starting with 0 to become more comfortable with it!
I rarely use do..while loops. Here’s the syntax.
do { console.log('How may I help you?'); // Help the customer numOfCustomers = numOfCustomers - 1;} while (numOfCustomer > 0);
Like C, the Javascript for loop has three clauses.
The initialization clause
The conditional clause
The update clause
Reusable pieces of code can be gathered into a function
The lexical scope, or scope, is the programming term to tell us where our variables can be accessed.
function outer() { var a = 1; function inner() { var b = 2; // we can access both `a` and `b` here console.log( a + b ); // 3 } inner(); // we can only access `a` here console.log( a ); // 1}outer();
In the example, you can’t call inner(); on the outermost scope. It can only be called within the outer function scope, as shown.
More on lexical scope in the first three chapters of Scope & Closures
Chapter 2. Into Javascript
Note: After reading through the first chapter, I realize I don’t really need to review too much. I’m going to skim this chapter and only note the things that I really think are worthwhile. Otherwise, I will keep notes on this chapter to a minimum.
No value set type is undefined.
I didn’t know null is an object type. Weird bug probably will never get fixed.
typeof null is an interesting case, because it errantly returns “object”, when you’d expect it to return “null”.
To learn: Javascript’s symbols. I’m well aware of Ruby’s implementation of symbols like :symbol_example, which are used in many different contexts like classes. Will elaborate more on this in the ES6 portion.
Arrays and functions are subtypes to objects. In my introduction to JS, I assumed “everything is an object”.
Built-In Type Methods extend the power of Javascript. These methods are like String.prototype.toUpperCase.
Coercion comes in two forms: explicit and implicit
explicit is with both types the same.
implicit is when type conversion can happen.
Coercion is not evil. There are times when you may need to convert types.
List of falsy:
"" (empty string)
0, -0, NaN
null, undefined
false
Things that can be truthy
non-empty strings
non-zero, valid numbers
true
arrays, empty or non-empty
objects, empty or non-empty
functions
== checks for value equality. Coercion allowed.
=== checks for value and type equality. Coercion not allowed. Also known as strict equality
Some simple rules for equality of when to use == or ===.
If either value (aka side) in a comparison could be the true or false value, avoid == and use ===.
If either value in a comparison could be of these specific values (0, "", or [] — empty array), avoid == and use ===.
In all other cases, you’re safe to use ==. Not only is it safe, but in many cases it simplifies your code in a way that improves readability.
I’ve played it safe with this, but I may revisit using == more often, if it doesn’t violate the rules. Important note: think critically before use.
You might think that two arrays with the same contents would be == equal, but they’re not
When comparing numbers with strings, the strings get coerced into a number. When the string contains non-number characters, it gets converted to NaN and when comparing with < or >, NaN is neither greater nor less than a value, hence returns false.
Hoisting is when a variable is moved to the top of the enclosing scope. (conceptually speaking)
Okay to use a function before it is declared as function declarations are hoisted. Generally not good with variables.
Use let for block scoped variables. For example, in an if block, you declare a variable you only want to be used within that block, use let.
function foo() { var a = 1; if (a >= 1) { let b = 2; while (b < 5) { let c = b * 2; b++; console.log( a + c ); } }}foo();// 5 7 9
Strict mode was introduced in ES5. Noted with "use strict".
Strict mode disallows implicit auto-global variable declaration from omitting the var.
I feel computer science needs to put unnecessarily long titles to items. Immediately invoked function expressions (IIFE) are involved upon declaration.
An example use case was with Highcharts and creating an options object. You can’t always assign a key with a function, so this is one way around it.
Closure is a way to “remember” and continue to access a function’s scope.
I think of this as a way to tweak functions without having to write out more functions.
This is least understood by JS developers, and I think I know why. To me, it’s a function generator, although that’s an improper term because Javascript can create a generator function, which is a totally different topic.
The most common usage of closure in Javascript is the module pattern. Modules let you define private implementation details (variables, functions) that are hidden from the outside world, as well as a public API that is accessible from the outside.
Executing the module as a function creates an instance of that module.
The this operator reference depends on how the function is called. That will determine what this is. There are four rules of how this gets set. More on this later in the this & Object Prototype book.
Prototype links allow one object to delegate properties from another object. What this means is a property prototype linked is not attached to that object but to its original object (which could in turn, just be the proto property of Object).
Do not think of applying prototypes as inheritance. It follows a pattern called “behavior delegation”, delegating one part of an object to another.
Bring the old to new with polyfiling and transpiling.
A “polyfill” is to take a definition of a newer feature and produce a piece of code equivalent to the behavior for older JS environments.
An example is lodash that has a bunch of features from ES5 and ES6 which some frameworks utilize, like forEach and map.
Careful writing your own polyfill as you should adhere closely to the specification.
Better yet, use the vetted ones.
Transpiling is great for new syntax. It is a tool that converts your code to older coding environments. You can break down the word “transpiling” into transforming + compiling.
arguments can be used functions to determine which arguments were passed in. It is not a reserved word, so you can assign it to a different value. When calling it, it outputs an array.
The book series doesn’t cover Non-Javascript, like the DOM API. But you need to be aware of it. DOM API could actually be written by the browsers in C/C++.
The document object is a “host object”, a special object that has been implemented by the browser.
Chapter 3: Into YDKJS
This chapter is a preface to the other books. I’ll skip these notes as I’ll be covering this in more detail in those posts.
I ran across the node-glob and realized I didn’t know what a glob is. I read through the node-glob documentation and found out globs are a form of pattern matching. I realized I had been using globs for a long time, like the wildcard notation, without knowing its name.
adventure time glob
Wildcards
There are generally two wildcards you can use for glob functions.
* - “any string of characters”
? - one character
There are also brackets, where the character must be one of the following, or given as a range.
[abc] - one of “a”, “b”, or “c”
[a-z] - between the range of “a” to “z”.
You can also line this up with a ”!” to mean not in the following bracket.
[!abc] - not one of “a”, “b”, or “c”
[!a-z] - not in the range of “a” to “z”
The examples above are used in UNIX-based systems. These commands are slightly different in Window’s Powershell and SQL. For more information about those systems, you can read the Wikipedia article about globs.
Node Example
var glob = require("glob");// options is optionalglob("**/*.js", options, function (er, files) { // files is an array of filenames. // If the `nonull` option is set, and nothing // was found, then files is ["**/*.js"] // er is an error object or null.});
I got into vim from a co-worker.
I thought it’s that clunky text editor in your terminal you must use when you have ssh into the linux server.
However, I’ve grown to understand vim is much more than a text editor.
It can also be an IDE.
When I first used vim, it just looked plain an boring.
The black screen with hard to understand shortcuts.
There weren’t any line numbers.
I didn’t even know how to exit the damn program for a good 5 minutes.
Then I started figuring it out slowly.
Vim has different modes.
Vim can do macros.
Vim can find things with the same grep commands.
And it’s quite expandable with the limitless plugins.
Vim is an endless rabbithole where you will get sucked in hours just setting it up.
But it’s your customization.
And that’s the beauty of vim.
Best advice - configure vim, and for that matter dotfiles, on your own.
Don’t blindly copy and paste configurations, because you’ll never understand them all.
Modal Editing
Quoted from Nick Nisi
Change the meaning of the keys in each mode of operation
Normal mode - navigate the structure of the file
Insert Mode - editing the file
Visual mode - highlighting portions of the file to manipulate at once
Ex mode - command mode
Line Numbers
Where are my line numbers?
Simply type the following.
:set number
To remove the numbers, you can use this command.
:set nonumber
Configuration
If you’re sick and tired of setting everything up every time you boot up vim, simply place the configuration in your configuration file.
You can find the configuration file at this location.
~/.vimrc
Here’s a truncated version of my general settings.
syntax enable " Enable syntax highlightingset tabstop=2 " set the tab stop at 2 spacesset shiftwidth=2 " set the shift width by 2 spacesset noexpandtab " do not expand tabset number " show line numbers
I’m currently using Monokai, mainly because it was a default I had with Ruby on sublime.
I set it up using vim-monokai, which I actually want to go back and figure out how to hook it up with vundle and have it linked to the repo.
I want to figure out how to do this better, so I placed a todo with the wiki from the vim wikia.
Vim tutor is a great guide to get you started with vim.
Getting Started
To start with Vim Tutor, simply type vimtutor in your terminal.
The tutorial says it should take about 25 to 30 minutes, but because I was also messing around with writing up this post and including their lesson summaries, all trying to use vim, I spend a bit longer with it.
If you’re running low on time, I’d say do each lesson in a 5 to 10 minute window span each day. You’re allowed to take it slow.
I learned it’s about the journey, not about the speed in which it takes for you to pick it up. It’s there where you can start nitpicking on how to do “x” or “y”.
The next following sections are summaries of what vim tutor teaches you. I modified some of the summaries to best fit markdown format.
Lesson 1 Summary
The cursor is moved using either the arrow keys or the hjkl keys.
h (left)
j (down)
k (up)
l (right)
To start Vim from the shell prompt type: vim FILENAME <ENTER>
To exit Vim type: <ESC>:q!<ENTER> to trash all changes.
OR type: <ESC>:wq<ENTER> to save the changes.
To delete the character at the cursor type: x
To insert or append text type:
i type inserted text <ESC> insert before the cursor
A type appended text <ESC> append after the line
NOTE: Pressing <ESC> will place you in Normal mode or will cancel an unwanted and partially completed command.
Lesson 2 Summary
To delete from the cursor up to the next word type: dw
To delete from the cursor to the end of a line type: d$
To delete a whole line type: dd
To repeat a motion prepend it with a number: 2w
The format for a change command is:
operator [number] motion
where:
- **operator** - is what to do, such as d for delete- **[number]** - is an optional count to repeat the motion- **motion** - moves over the text to operate on, such as w (word), (to the end of line), etc.
6. To move to the start of the line use a zero: 0
Undo & redo actions
To undo previous actions, type: u (lowercase u)
To undo all the changes on a line, type: U (capital U)
To undo the undo’s, type: CTRL-R
Lesson 3 Summary
To put back text that has just been deleted, type p . This puts the
deleted text AFTER the cursor (if a line was deleted it will go on the
line below the cursor).
To replace the character under the cursor, type r and then the
character you want to have there.
The change operator allows you to change from the cursor to where the
motion takes you. eg. Type ce to change from the cursor to the end of
the word, c$ to change to the end of a line.
The format for change is:
c [number] motion
Lesson 4 Summary
CTRL-G displays your location in the file and the file status.
G moves to the end of the file.
[number] G moves to that line number.
gg moves to the first line.
Find command
Typing / followed by a phrase searches FORWARD for the phrase.
Typing ? followed by a phrase searches BACKWARD for the phrase.
After a search type n to find the next occurrence in the same direction
or N to search in the opposite direction.
CTRL-O takes you back to older positions, CTRL-I to newer positions.
Typing % while the cursor is on a ( , ), [, ], {, or } goes to its match.
Substitute command
To substitute new for the first old in a line type :s/old/new
To substitute new for all ‘old’s on a line type :s/old/new/g
To substitute phrases between two line #‘s type :#,#s/old/new/g
To substitute all occurrences in the file type :%s/old/new/g
To ask for confirmation each time add c:%s/old/new/gc
Lesson 5 Summary
:!command executes an external command.
Some useful examples are:
(MS-DOS)
(Unix)
description
:!dir
:!ls
shows a directory listing
:!del FILENAME
:!rm FILENAME
removes file FILENAME
:w FILENAME writes the current Vim file to disk with name FILENAME.
v motion :w FILENAME saves the Visually selected lines in file FILENAME.
:r FILENAME retrieves disk file FILENAME and puts it below the cursor position.
:r !dir reads the output of the dir command and puts it below the cursor position.
Lesson 6 Summary
Open a line in insert mode
Type o to open a line BELOW the cursor and start Insert mode.
Type O to open a line ABOVE the cursor.
Append text
Type a to insert text AFTER the cursor.
Type A to insert text after the end of the line.
The e command moves to the end of a word.
The y operator yanks (copies) text, p puts (pastes) it.
Typing a capital R enters Replace mode until <ESC> is pressed.
Typing :set xxx sets the option xxx. Some options are:
icignorecase ignore upper/lower case when searching
isincsearch show partial matches for a search phrase
hlshlsearch highlight all matching phrases
You can either use the long or the short option name.
Prepend no to switch an option off: :set noic
Lesson 7 Summary
Type :help or press <F1> or <Help> to open a help window.
Type :help cmd to find help on cmd.
Type CTRL-W CTRL-W to jump to another window
Type :q to close the help window
Create a vimrc startup script to keep your preferred settings.
When typing a : command, press CTRL-D to see possible completions. Press <TAB> to use one completion.
Post Tutorial Reflection
The tutorial got me through the basics, and only scraps the surface of what you can do with vim. One of the things I found useful after going through this tutorial was saying out loud what the command I was using does.
For example, if I was using the w command, I would say “word”. If I was going to the word, and I was using the diw command, I would say “delete instance word”. Using words instead of letters helps with getting the commands down. It’s the same technique I used when learning the bash terminal, e.g. with pwd, I would say in my head, “print working directory”.
I wrote up a much longer post about vim that I will publish soon.